This chapter covers
- Kafka tools, including GUIs, GitOps concepts, and Cruise Control
- Kafka’s deployment models
- Key hardware requirements for Kafka brokers
Now that we’ve gained a good overview of what Kafka is, how we use it, and how it integrates architecturally into our existing enterprise IT landscapes, the big question arises: What do we need to operate Kafka successfully? As discussed in the previous chapters, Kafka alone is often insufficient to achieve our enterprise goals. A typical Kafka setup consists of much more than just the brokers and coordination cluster, as depicted in figure 14.1.
We need additional components for a successful Kafka environment. First and foremost, the applications that use Kafka are very important, such as simple producers and consumers that write data to or read from Kafka. We can use Java producers and consumers without restrictions. As mentioned in chapter 8, for non-Java producers, it’s crucial to ensure that they use the same partitioning algorithm as Java producers to avoid potential problems.
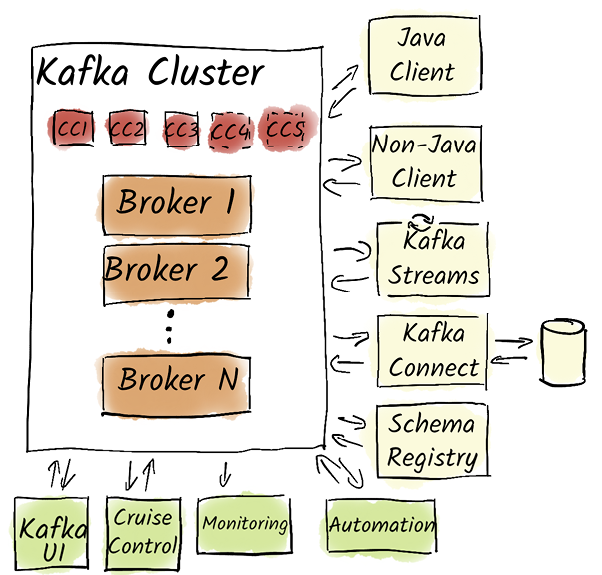
In many cases, we don’t even need custom producers and consumers to send data from third-party systems to Kafka or from Kafka to other systems. Many of these use cases can be elegantly solved with Kafka Connect without writing custom code. We extensively discussed the pros and cons of this solution in chapter 11.