Chapter 9. An example batch layer: Implementation
This chapter covers
- Ingesting new data into the master dataset
- Managing the details of a batch workflow
- Integrating Thrift-based graph schemas, Pail, and JCascalog
In the last chapter you saw the architecture and algorithms for the batch layer for SuperWebAnalytics.com. Let’s now translate that to a complete working implementation using the tools you’ve learned about like Thrift, Pail, and JCascalog. In the process, you’ll see that the code matches the pipe diagrams and workflows developed in the previous chapter very closely. This is a sign that the abstractions used are sound, because you can write code similar to how you think about the problems.
As always happens with real-world tools, you’ll encounter friction from artificial complexities of the tooling. In this case, you’ll see certain complexities arise from Hadoop’s limitations regarding small files, and those complexities will have to be worked around. There’s great value in understanding not just the ideal workflow and algorithms, but the nuts and bolts of implementing them in practice.
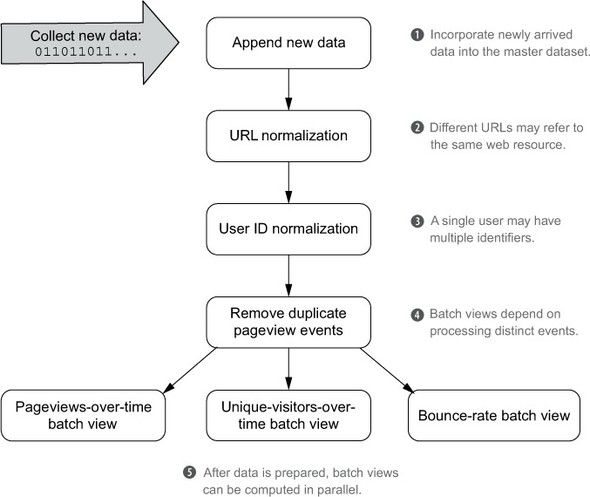
The workflow developed in the previous chapter is repeated in figure 9.1. You’re encouraged to look back at the previous chapter to refresh your memory on what each step of the workflow does.