2 Solving the inference bottleneck with the key-value cache
This chapter covers
- The inefficiency of autoregressive LLM inference
- The key-value cache: a solution with a cost
- MQA and GQA: First-Gen Solutions to KV cache memory limits
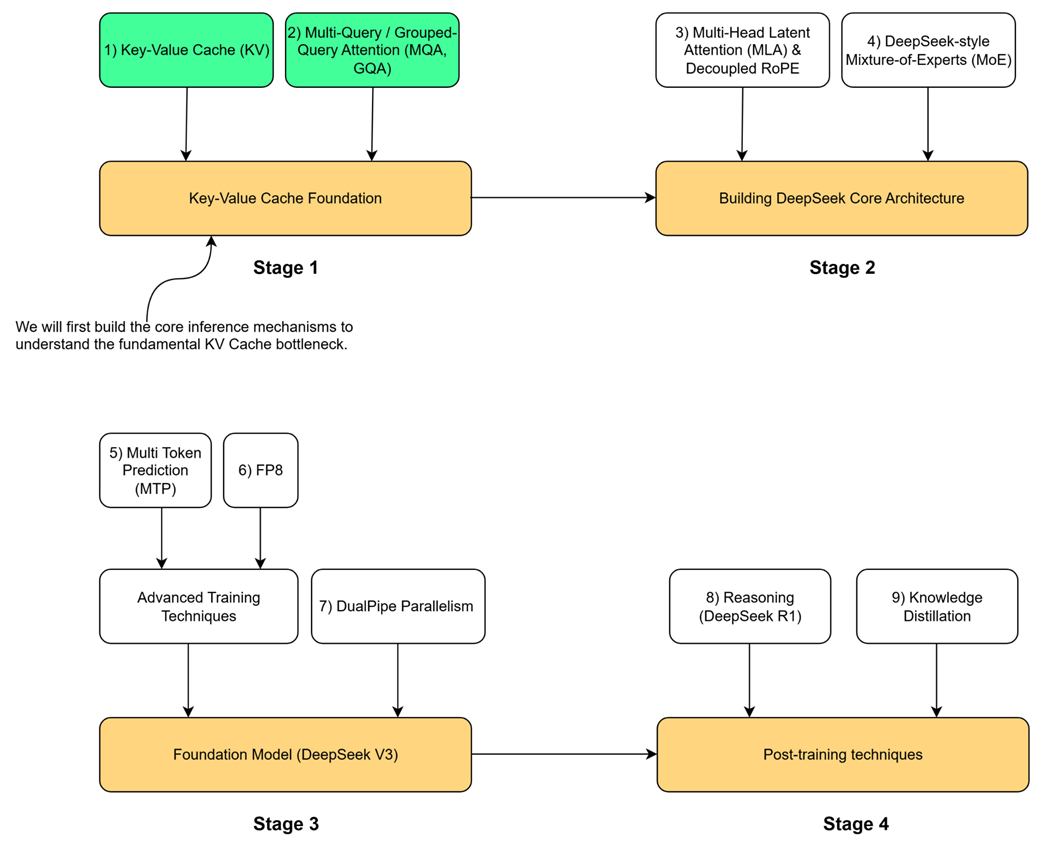
To understand the key innovations in the DeepSeek architecture, we must begin with the technical problem it was designed to address. Our journey follows the four-stage roadmap outlined at the start of this book, and this chapter is dedicated entirely to Stage 1: the key-value cache foundation. This stage addresses the most fundamental bottleneck in modern LLM inference. Before we can appreciate advanced architectural choices like DeepSeek's Multi-Head Latent Attention (MLA) in Stage 2, we must first understand the mechanisms it evolved from and the problems it was designed to solve.
2.1 The LLM inference loop: Generating text one token at a time
2.1.1 Distinguishing pretraining from inference
2.1.2 Autoregressive process: Appending tokens to build context
2.1.3 Visualizing autoregressive generation with GPT-2
2.2 The core task: Predicting the next token
2.2.1 From input embeddings to context vectors: A mathematical walkthrough
2.2.2 From context vectors to logits
2.2.3 The key insight: Why only the last row matters
2.3 The problem of redundant computations
2.3.1 Intuition: Are we calculating the same thing over and over?
2.3.2 A mathematical proof: Visualizing repeated calculations
2.3.3 The performance effect: From quadratic to linear complexity
2.4 The solution: Caching for efficiency
2.4.1 What to cache? A step-by-step derivation
2.4.2 The new inference loop with KV caching
2.4.3 Demonstrating the speedup of KV caching
2.5 The dark side of the KV cache: The memory cost
2.5.1 The KV cache formula: Deconstructing the size
2.5.2 The scaling problem in practice
2.6 The memory-first approach: Multi-Query Attention (MQA)
2.6.1 The core idea: Sharing a single key and value projection
2.6.2 The impact on the KV cache formula
2.6.3 The performance trade-off: Loss of expressivity
2.6.4 Implementing an MQA layer from scratch
2.7 The middle ground: Grouped-Query Attention (GQA)
2.7.1 The core idea: Sharing keys and values within groups
2.7.2 The tunable knob: Balancing memory and performance
2.7.3 Implementing a GQA layer from scratch