6 The DeepSeek training pipeline: Building a foundation model
This chapter covers
- Assembling the DeepSeek V3 architecture
- Building a complete data and training pipeline
- DualPipe Parallelism for efficient scaling
We’ve deconstructed DeepSeek’s core innovations: Multi-Head Latent Attention, Decoupled RoPE, DeepSeek Mixture-of-Experts layer, and the Multi-Toke
n Prediction training objective. We have explored the theory and even built some of these components in isolation. Now, it's time to put it all together, transitioning from individual components to a complete, functional system.
We will integrate all these advanced concepts into a single PyTorch model, a "mini-DeepSeek V3" that you can train from scratch on your own hardware. This hands-on process is the final step in truly understanding how these theoretical pieces interact in a real-world training environment. Our journey covers the entire pipeline, from raw data to a working, text-generating model.
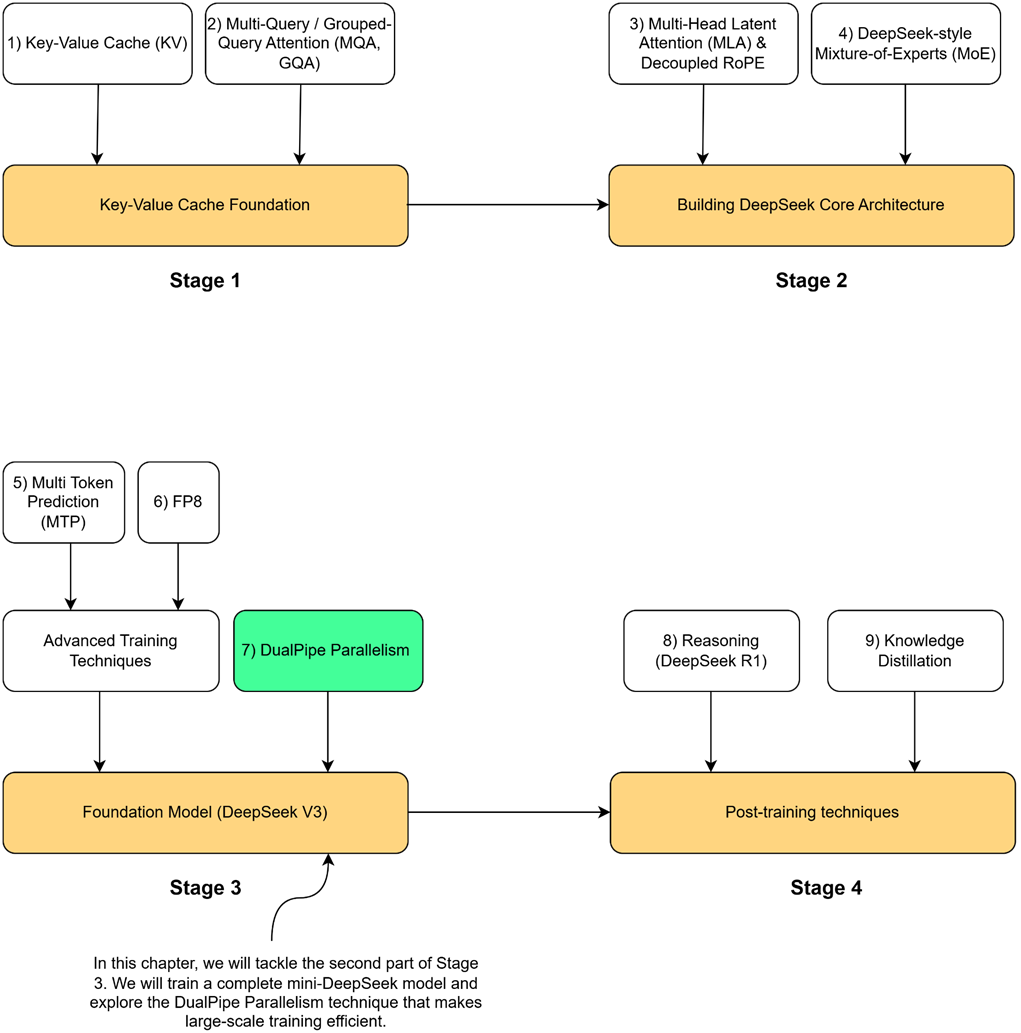
Figure 6.1 Our four-stage journey to build the DeepSeek model. This chapter is dedicated to part 2 of Stage 3, where we take the core architecture from Stage 2, combine it with advanced training techniques like MTP and FP8, and build a complete foundation model. We will also introduce the final training innovation, DualPipe Parallelism.