chapter seven
7 Finetuning to Follow Instructions
This chapter covers
- Introduction to the instruction finetuning process of LLMs
- Preparing a dataset for supervised instruction finetuning
- Organizing instruction data in training batches
- Loading a pretrained LLM and finetuning it to follow human instructions
- Extracting LLM-generated instruction responses for evaluation
- Evaluating an instruction-finetuned LLM
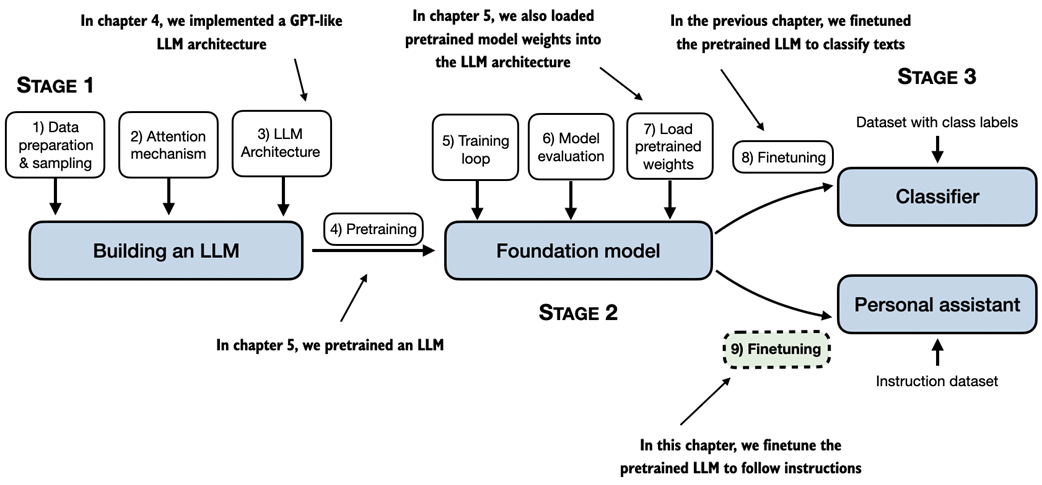
In previous chapters, we implemented the LLM architecture, carried out pretraining, and imported pretrained weights from external sources into our model. Then, in the previous chapter, we focused on finetuning our LLM for a specific classification task: distinguishing between spam and non-spam text messages. In this chapter, we implement the process for finetuning an LLM to follow human instructions, as illustrated in figure 7.1, which is one of the main techniques behind developing LLMs for chatbot applications, personal assistants, and other conversational tasks.
Figure 7.1 A mental model of the three main stages of coding an LLM, pretraining the LLM on a general text dataset, and finetuning it. This chapter focuses on finetuning a pretrained LLM to follow human instructions.