This chapter covers
- BentoML for model serving and building model servers
- Observability and monitoring in BentoML
- Packaging and deploying BentoML Services
- Using BentoML and MLflow together
- Using only MLflow for model life cycles
- Alternatives to BentoML and MLflow
Now that we have a working model training and validation pipeline, it’s time to make the model available as a service. In this chapter, we’ll explore how to seamlessly serve your object detection model and movie recommendation model using BentoML, a powerful framework designed to build and serve ML models at scale.
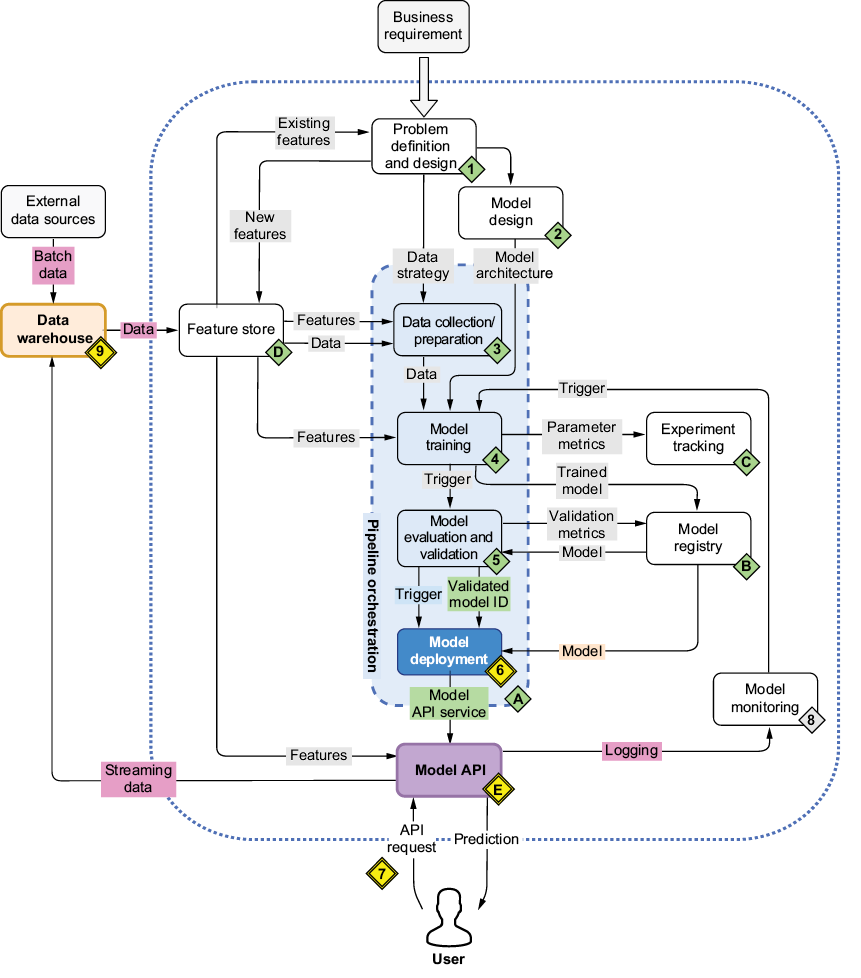
You’ll have the opportunity to deploy the two models you trained in the previous two chapters, gaining hands-on experience with real-world deployment scenarios. We’ll start by building and deploying the service locally, and then we’ll progress to creating a container that encapsulates a service for deployment, integrating it seamlessly into your ML workflow (figure 10.1).
Figure 10.1 The mental map where we’re now focusing on model deployment (6) and making the model available as an API (E)
Self-service model deployment offers several advantages for engineers developing machine learning operations (MLOps):