8 Model training and validation: Part 1
This chapter covers
- How to design modular training components
- Capturing metrics and artifacts in tracking frameworks
- Adding the Model Training and Validation components to pipelines
- Different methods to access training and evaluation data
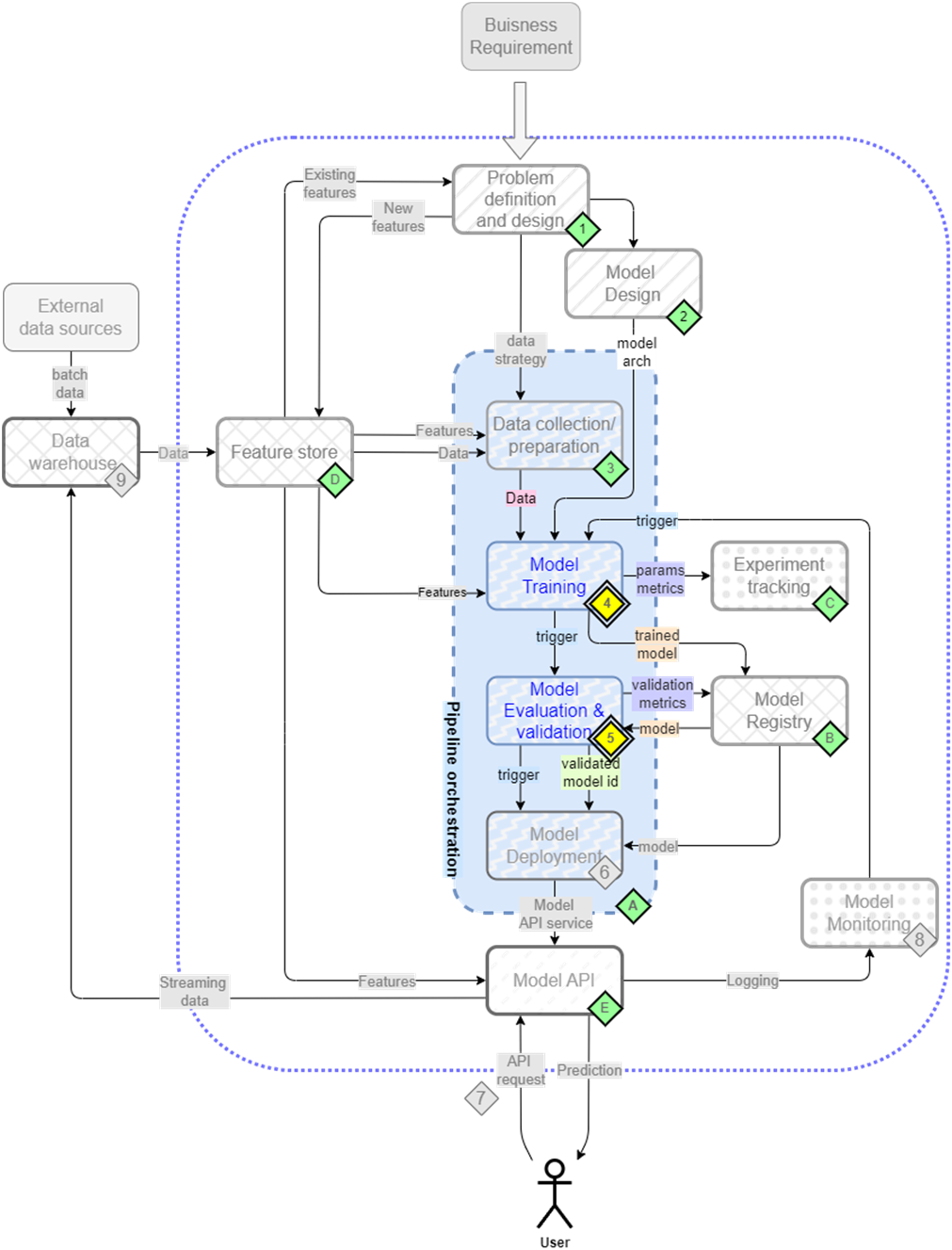
Building reliable ML systems requires more than just accurate models - it demands reproducible training processes and robust validation strategies. In this chapter, we'll build on our data preparation pipeline to create production-ready training and validation components (Figure 8.1).
Figure 8.1 The mental map where we are now focusing the second and third step/component of our pipeline - model training(4) and evaluation(5)
Through hands-on examples using YOLO object detection, you'll learn to develop modular training components that can scale from experimentation to production. We'll explore the intricacies of model validation in real-world scenarios, see how to effectively capture and track metrics for model improvement, and master techniques for seamlessly integrating these components into your ML pipelines.
By leveraging these practices with our ID card detection system and later applying them to a movie recommendation system, you'll gain practical experience in building robust training workflows that form the backbone of production ML systems.