appendix C Qwen3 LLM source code
Although this is a “from scratch” book, that part of the title refers to the reasoning techniques, not to the LLM itself. Implementing an LLM entirely from scratch would require a separate book, such as my Build a Large Language Model (From Scratch), also available from Manning (http://mng.bz/orYv).
If you’re interested in the Qwen3 implementation used in this book, this appendix lists the source code for the Qwen3Model model that I implemented and that we import from the book’s reasoning_from_scratch Python package:
from reasoning_from_scratch.qwen3 import Qwen3Model, Qwen3Tokenizer
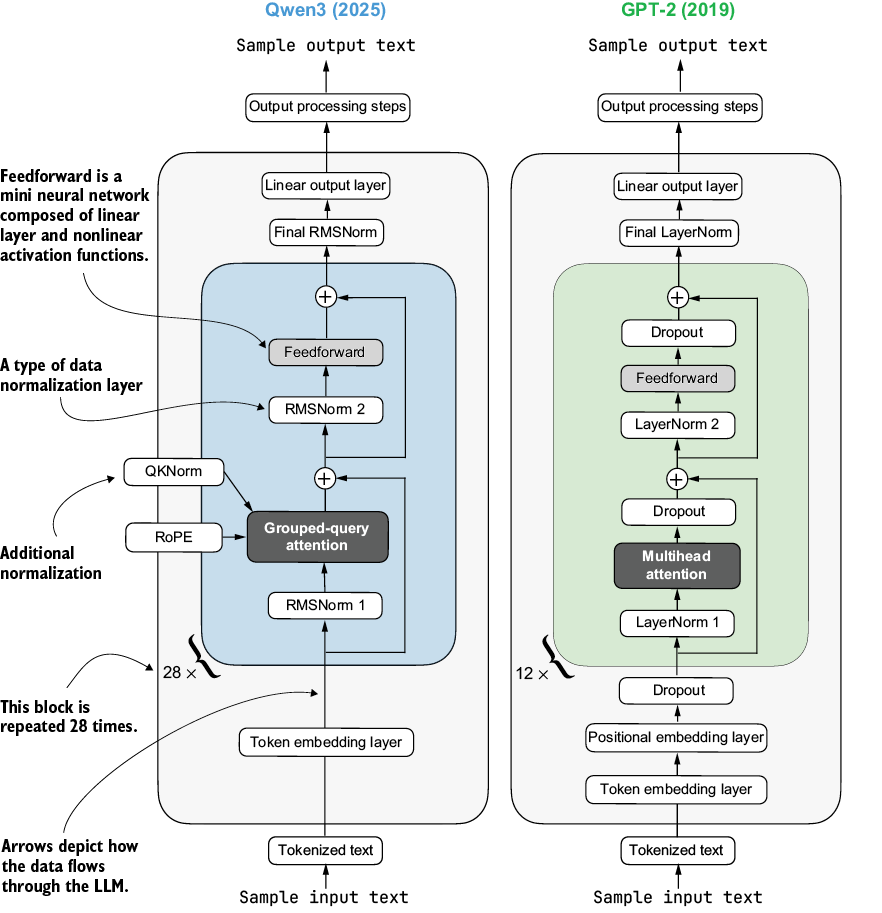
As shown in figure C.1, the Qwen3 architecture is very similar to GPT-2, which I cover in my Build A Large Language Model (From Scratch) book. While familiarity with GPT-2 is not required for this book, this appendix includes comparisons to GPT-2 for readers who are familiar with it. In fact, I wrote the Qwen3 implementation by porting the GPT-2 model from my other book, piece by piece, into the Qwen3 architecture so that it follows similar style conventions and is easier to read.
Figure C.1 Architectural comparison between Qwen3 and GPT-2. Both models process text through embedding layers and stacked transformer blocks, but they differ in certain design choices.