appendix E Batching and throughput-oriented execution
In the code implemented through the book’s chapters, we usually processed one prompt or example at a time. This kept the code compact and easier to understand, and it also helped keep the resource requirements more manageable. The code in this book is already expensive to run, so adding batching support everywhere would often increase complexity without providing much real benefit, depending on your available hardware.
That being said, if you have access to relatively modern GPUs with enough memory, batched execution, illustrated in figure E.1, can be very useful. For example, if we want to evaluate many problems, sample several responses per prompt, or train on multiple examples at once, batching can help increase throughput and reduce the overall time required.
Figure E.1 An overview of single-example versus batched generation. In batched generation, several prompts are packed into one batch, processed in parallel, and then decoded together to improve throughput.
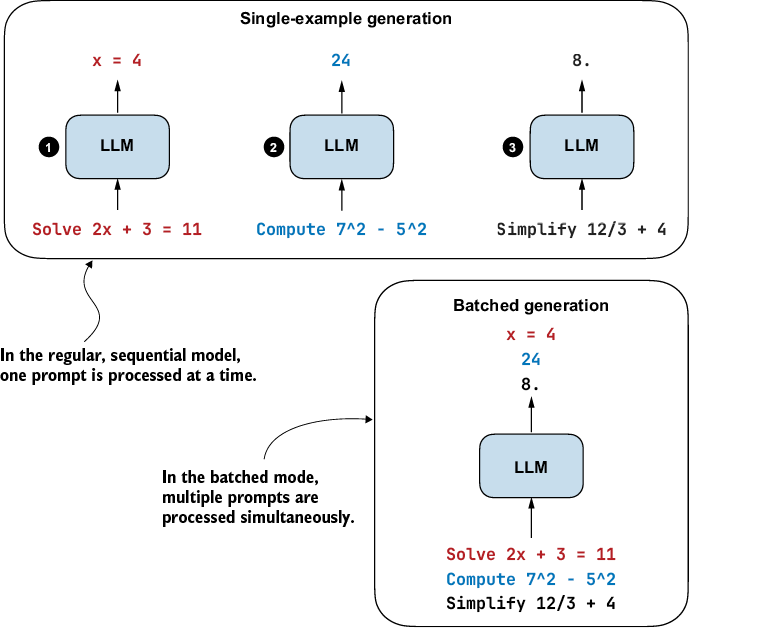
This appendix explains the broad idea behind batching and shows how you can use the batched implementations in the supplementary materials across various chapters.
E.1 Why batching helps
When we talk about computational performance, it helps to separate the following overall goals:
- Latency: how quickly we get the answer for one prompt
- Throughput: how many prompts we can process in a fixed amount of time