appendix F Common approaches to model evaluation
F.1 Understanding the main evaluation methods for LLMs
There are four common ways of evaluating trained LLMs in practice: multiple choice, verifiers, leaderboards, and LLM judges, as shown in figure F.1. Research papers, marketing materials, technical reports, and model cards (a term for LLM-specific technical reports) often include results from two or more of these categories.
Figure F.1 A model of the topics covered in this book, with a focus on the two broad evaluation categories covered in this appendix: benchmark-based evaluation and judgment-based evaluation
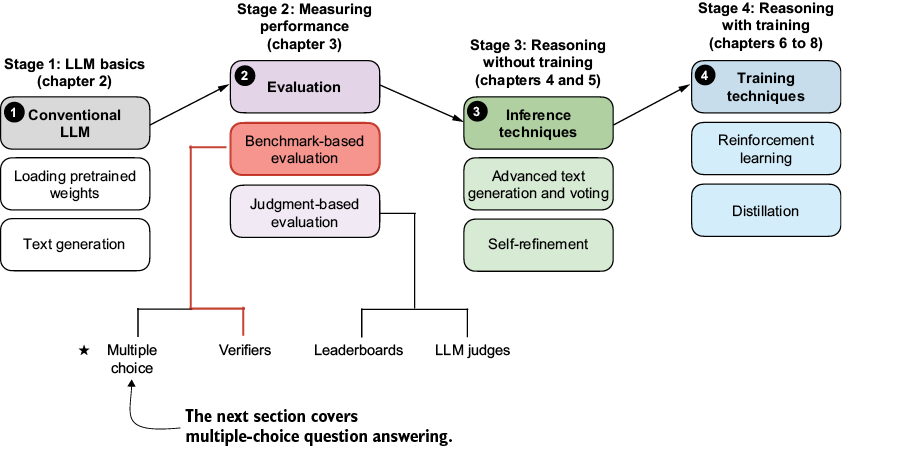
As you can see in figure F.1, the four evaluation categories introduced here fall into two groups: benchmark-based evaluation and judgment-based evaluation. Other measures, such as training loss, perplexity, and rewards, are typically used internally during model development. They are covered in the model-training chapters (chapters 6 to 8).
F.2 Evaluating answer-choice accuracy
Historically, one of the most widely used evaluation methods has been multiple-choice benchmarks such as MMLU (short for Massive Multitask Language Understanding, https://huggingface.co/datasets/cais/mmlu).