5 Inference-time scaling via self-refinement
This chapter covers
- Scoring LLM answers with a simple rule-based scorer
- Computing an LLM’s confidence in its answers
- Coding a self-refinement loop where the LLM iteratively improves its answers
The previous chapter introduced the concept of inference-time scaling (inference scaling for short), which improves the accuracy of model responses without further training. In particular, it focused on self-consistency, where the model generates multiple answers, and the final answer is the most frequent one.
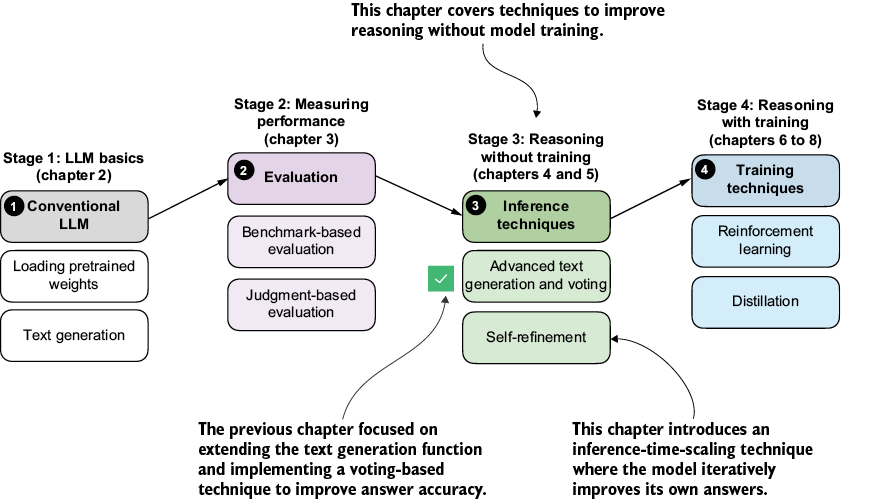
As outlined in figure 5.1, this chapter will move beyond self-consistency for inference scaling and cover another popular and useful inference-scaling technique, self-refinement. Instead of generating and choosing from multiple answers, self-refinement focuses on iteratively refining a single answer to correct potential mistakes.
Figure 5.1 A model of the topics covered in this book. This chapter continues with stage 3 and focuses on inference-time techniques for improving reasoning without additional training. It introduces self-refinement, where the model iteratively critiques and improves its own answers.
5.1 Scoring and iteratively improving model responses
As you’ve seen, inference scaling trades additional compute for better accuracy. We’ve covered two inference-scaling techniques so far: chain-of-thought prompting and self-consistency.