chapter six
6 Training reasoning models with reinforcement learning
This chapter covers
- The difference between reinforcement learning with human feedback and reinforcement learning with verifiable rewards
- Training reasoning LLMs as a reinforcement learning problem with task-correctness rewards
- Sampling multiple responses per prompt to compute group-relative learning signals
- Updating the LLM weights using group-based policy optimization for improved reasoning
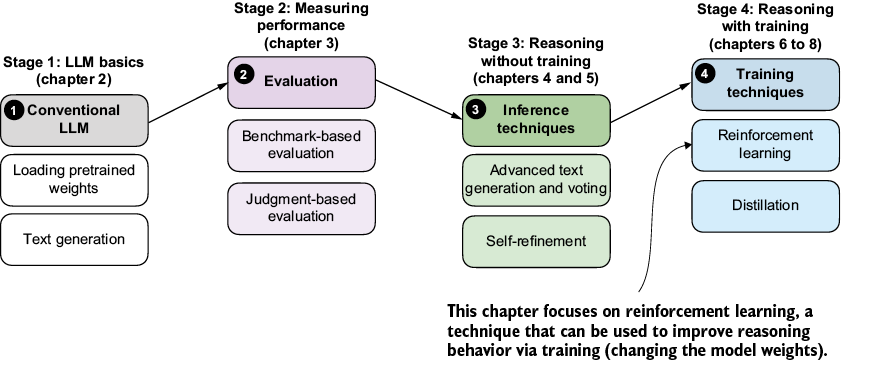
Reasoning performance and answer accuracy can be improved both by increasing the inference compute budget and by using specific model-training methods. This chapter, as shown in figure 6.1, focuses on reinforcement learning (RL), the most commonly used training method for reasoning models.
Figure 6.1 A model of the topics covered in this book. This chapter focuses on techniques that improve reasoning with additional training (stage 4). Specifically, this chapter covers reinforcement learning (RL).
We’ll first go through a general introduction to RL in the context of LLMs. Then we’ll discuss the two most common RL approaches used for LLMs.