7 Improving GRPO for reinforcement learning
This chapter covers
- Interpreting training curves and evaluation metrics
- Preventing the model from exploiting the reward signal
- Extending task-correctness rewards with additional response-formatting rewards
Previously, we implemented the GRPO algorithm for reinforcement learning with verifiable rewards (RLVR) from end to end. Now, as shown in figure 7.1, we’ll pick up from that baseline and focus on what happens when we run longer training.
Figure 7.1 A model of the topics covered in this book. This chapter provides deeper coverage of the GRPO algorithm for reinforcement learning with verifiable rewards.
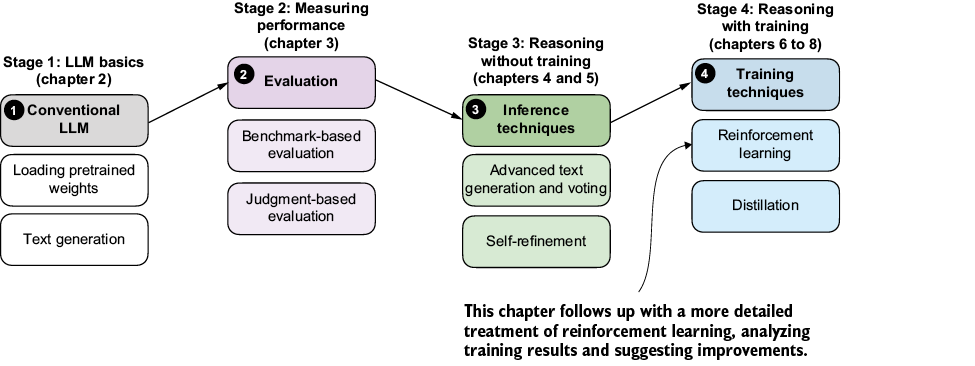
In particular, we’ll discuss which metrics are worth tracking (beyond reward and accuracy), how to spot failure modes early, and why training can become unstable even when the code is “correct.” As it turns out, basic GRPO can lead to training instability, so this chapter also introduces practical GRPO extensions and fixes that are used in reasoning-model training.
7.1 Improving GRPO
We implemented GRPO (Group Relative Policy Optimization) in the previous chapter; we’ll now revisit the training run and analyze it more thoroughly. We’ll also revisit the KL loss term that we omitted in the previous chapter and discuss some practical tips and algorithmic choices that become important in real training runs. These topics are summarized in the chapter overview in figure 7.2.