chapter eleven
This chapter covers
- Encoding images into continuous latent representations
- Quantizing latent representations into discrete codes using a codebook
- Reconstructing images from discrete sequences
- Understanding perceptual loss, adversarial loss, and quantization loss
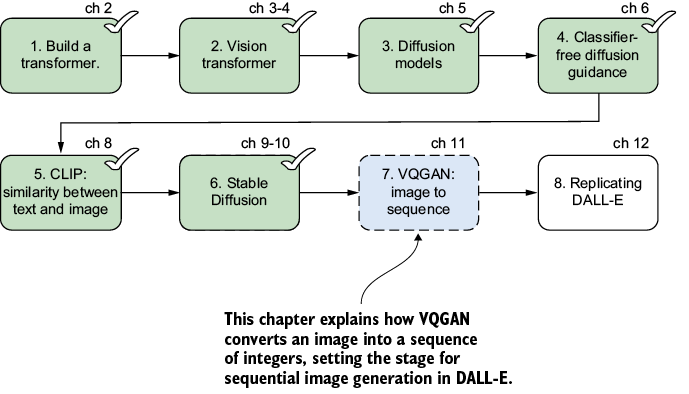
Modern transformer-based text-to-image models, such as DALL-E, rely on a crucial step: transforming images into sequences of discrete tokens, just as language models treat text as sequences of word tokens. Figure 11.1 shows how this step fits into the larger journey of building a text-to-image generator. In this chapter, we zero in on step 7, where vector quantized generative adversarial network (VQGAN) bridges the gap between images and language-like data, making images accessible to transformers.
Figure 11.1 Eight steps for building a text-to-image generator from scratch. This chapter focuses on step 7: transforming an image into a sequence of integers using VQGAN. By achieving this, we unlock the ability to generate images sequentially with transformer models, a critical advance that powers state-of-the-art systems such as DALL-E.