6 Creating Effective AI Agents
This chapter covers
- The limitations of standalone LLMs and how AI agents address these challenges
- The core components of reliable agents, including memory systems, tool integration, and decision-making frameworks
- Building and deploying agents with a focus on reliability, performance, and real-world applications
Imagine asking a cutting-edge AI to book a flight or manage your schedule. Despite its impressive ability to understand language, it can't perform real-world actions, leaving you to handle the details. This is where AI agents come in, transforming powerful but passive LLMs into active task managers. Imagine asking an LLM to help book a flight. One might ask:
An LLM might respond with a general suggestion:
This is hardly helpful. The LLM understands the question but can’t connect to flight APIs, check live schedules, or book the ticket. It simply lacks the ability to interact with the real world.
Figure 6.1 Core differences between a Standalone LLM and AI Agent
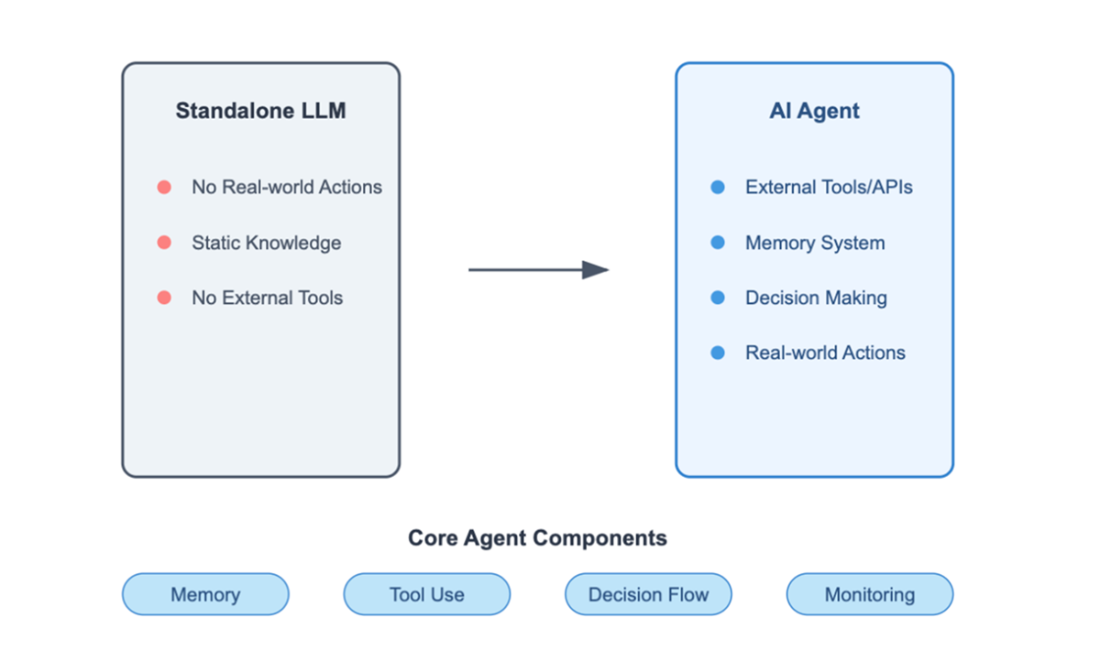
An AI agent (figure 6.1) bridges the gap between LLMs and real-world systems. While an LLM provides reasoning and language, the agent adds the ability to: