chapter twelve
12 Combining data sources into a unified dataset
This chapter covers
- Loading and processing raw data files
- Implementing a Python class to represent our data
- Converting our data into a format usable by PyTorch
- Visualizing the training and validation data
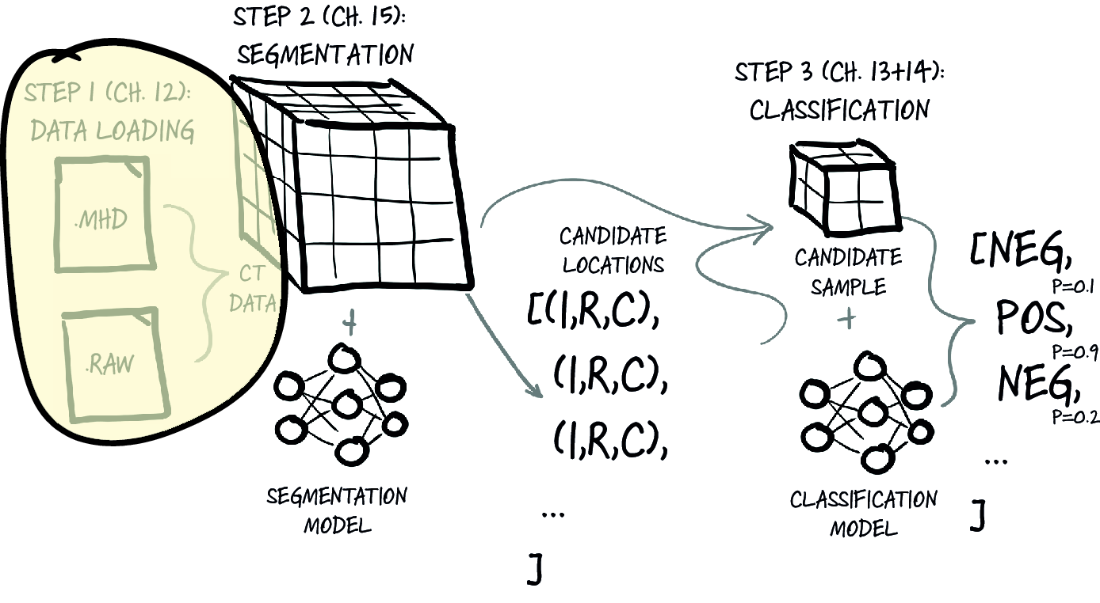
Now that we’ve discussed the high-level goals for our project, as well as outlined how the data will flow through our system, let’s get into the specifics of what we’re going to do in this chapter. It’s time to implement basic data-loading and data-processing routines for our raw data. The techniques we cover here are foundational and will be applicable to any major project you undertake. To the rare researcher who has all their data well prepared for them in advance: lucky you! The rest of us will be busy writing code for loading and parsing. Figure 12.1 shows the high-level map of our project from chapter 11. We’ll focus on step 1, data loading, for the rest of this chapter.
Figure 12.1 Our end-to-end lung-cancer-detection project, with a focus on this chapter’s topic: step 1, data loading