The close of the last chapter left us in a predicament. While we were able to get the mechanics of our deep learning project in place, none of the results were actually useful; the network simply classified everything as non-nodule! To make matters worse, the results seemed great on the surface, since we were looking at the overall percent of the training and validation sets that were classified correctly. With our data heavily skewed toward negative samples, blindly calling everything negative is a quick and easy way for our model to score well. Too bad doing so makes the model basically useless!
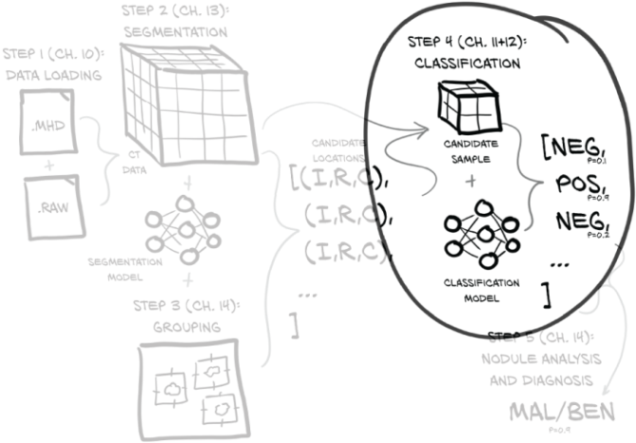
That means we’re still focused on the same part of figure 12.1 as we were in chapter 11. But now we’re working on getting our classification model working well instead of at all. This chapter is all about how to measure, quantify, express, and then improve on how well our model is doing its job.