3 End-to-end transformer fine-tuning
This chapter covers
- Specializing a very small language model to generate working Manim code
- The hyperparameter tuning process in transformer fine-tuning
- Evaluating the quality of the generated code
This chapter walks through an end-to-end example of fine-tuning a small model (GPT-2 small) for a specific task. This approach will apply to fine-tuning any GPT-like model for generative tasks.
3.1 Data preparation
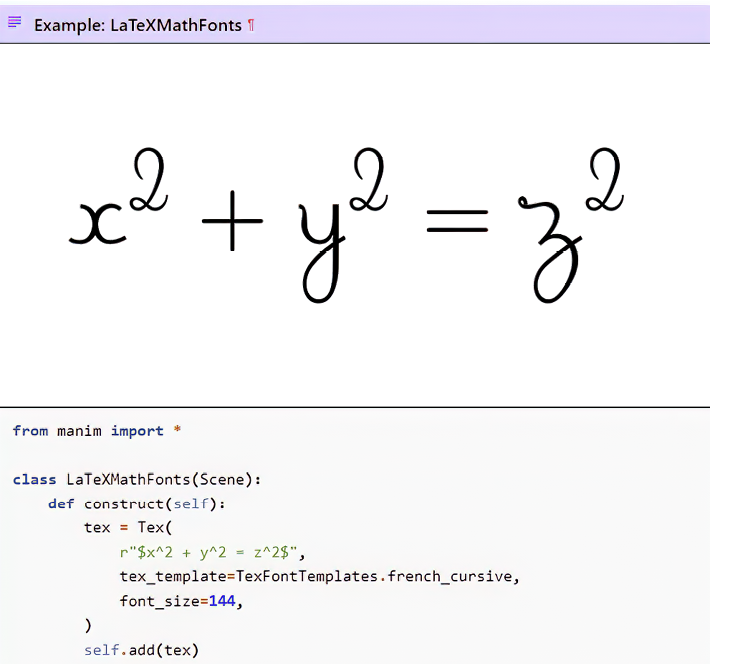
In this chapter, we’ll fine-tune the GPT-2 small model (https://huggingface.co/openai-community/gpt2) to generate working Manim code from natural-language prompts. Manim (https://github.com/ManimCommunity/manim) is an open source Python animation engine for explanatory math videos—it creates precise animations programmatically. Figure 3.1 shows an example of Manim code and its rendering.
Figure 3.1 An example of Manim code (bottom) and the corresponding rendering (top)
I chose GPT-2 small as a baseline not only because it can’t produce Manim code, but also to show that you can start with a small model and a high-quality, domain-specific dataset—even a relatively small one—and still specialize it for a task and achieve good performance. A companion Colab notebook contains the full source code from this chapter. Hardware acceleration (GPU, free tier) is required.