5 Exploring ONNX
This chapter covers
- The ONNX standard format
- The ONNX runtime
- How ONNX can be useful for LLMs, with or without hardware acceleration
This chapter introduces the ONNX framework, which plays an important role in model optimization, quantization, and portability across frameworks and hardware vendors. If you’re new to ONNX, take the time to absorb the concepts in this chapter—they’re used heavily in later chapters.
5.1 The ONNX format
ONNX (Open Neural Network Exchange, https://onnx.ai/) is an open standard for ML interoperability. First released in 2017, it is now a graduate project of the Linux Foundation for Artificial Intelligence (LFAI, https://lfaidata.foundation/). ONNX aims to improve interoperability across machine learning (ML) and deep learning (DL) frameworks (including Keras, TensorFlow, PyTorch, scikit-learn, XGBoost, and others) and to maximize performance across hardware accelerators (not just NVIDIA, but also Intel OpenVINO, Habana, Qualcomm, Apache TVM, Hugging Face Optimum, and more). Figure 5.1 gives a high-level view of the ONNX ecosystem, including the framework- and platform-agnostic model format and the optional ONNX Runtime.
Figure 5.1 ONNX overview
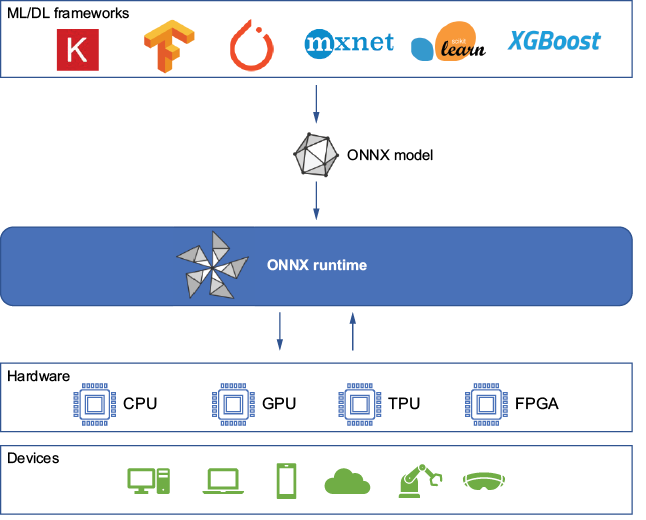
As ML and DL frameworks evolve, portability becomes critical—what we use today may not be what we’ll use tomorrow. ONNX is a robust open standard that reduces lock-in to specific frameworks and hardware accelerators, helping ensure an organization’s models remain usable over time.