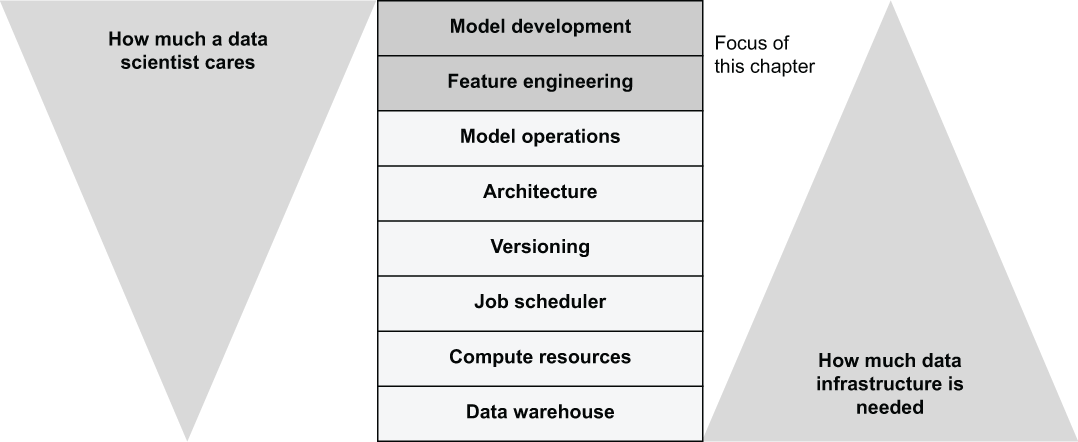
We have now covered all layers of the infrastructure stack, shown in figure 9.1, except the topmost one: model development. We only scratched the surface of the feature engineering layer in chapter 7. Isn’t it paradoxical that a book about machine learning and data science infrastructure spends so little time talking about the core concerns of machine learning: models and features?
The focus is deliberate. First, many excellent books already exist about these topics. Mature modeling libraries like TensorFlow and PyTorch come with a plethora of in-depth documentation and examples. As depicted in figure 9.1, these topics tend to be the core areas of expertise of professional data scientists and machine learning engineers, whereas the lower layers are not. To boost the day-to-day productivity of data scientists effectively, it makes sense to help them where help is needed the most: the lower layers of the stack.