Now that you have a to-do HTTP server in place, it’s time to make it more reliable. To have a truly reliable system, you need to run it on multiple machines. A single machine represents a single point of failure because a machine crash leads to a system crash. In contrast, with a cluster of multiple machines, a system can continue providing service even when individual machines are taken down.
Moreover, by clustering multiple machines, you have a chance of scaling horizontally. When demand for the system increases, you can add more machines to the cluster to accommodate the extra load. This idea is illustrated in figure 12.1.
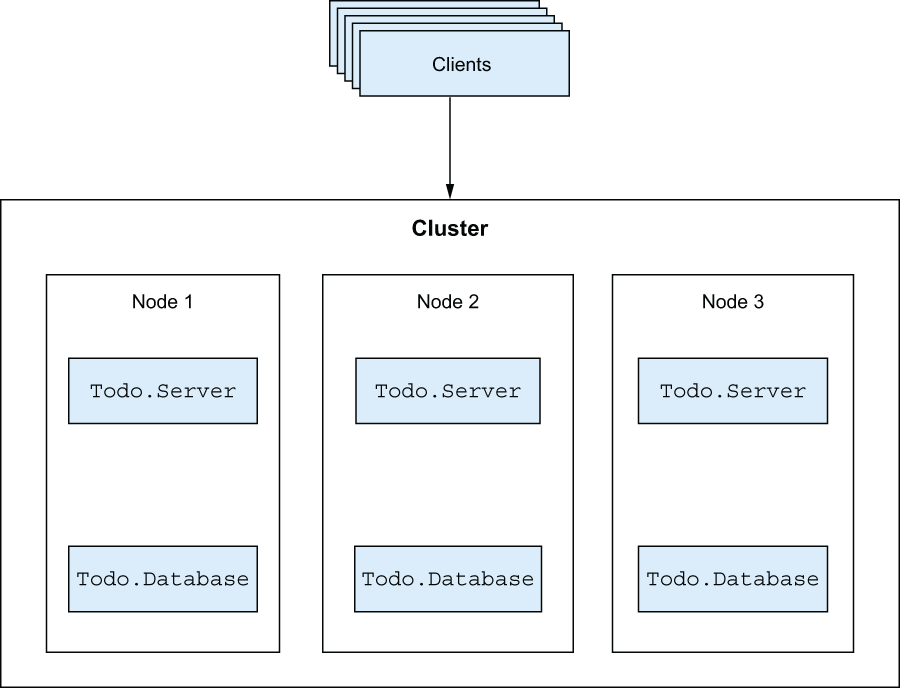
Here, you have multiple nodes sharing the load. If a node crashes, the remaining load will be spread across survivors, and you can continue to provide service. If the load increases, you can add more nodes to the cluster to take the extra load. Clients access a well-defined endpoint and are unaware of internal cluster details.