3 Ingestion 1: Building a search from scratch
This chapter covers
- Different chunking strategies
- Preprocessing raw data into embeddings
- Tagging vector data with metadata
- Ingesting data into vector databases for search
Now that we’ve covered evaluations (evals) and their critical role in creating an enterprise Retrieval-Augmented Generation (RAG) system, it’s time to move on to the next key phase: ingesting source data. The accuracy and usefulness of a RAG system’s responses depend heavily on the quality and format of the data it’s given. To ensure the Large Language Model (LLM) generates helpful, factually correct answers, we must provide it with the most relevant context. This process—selecting, preparing, and feeding data into the system—is what we call data ingestion.
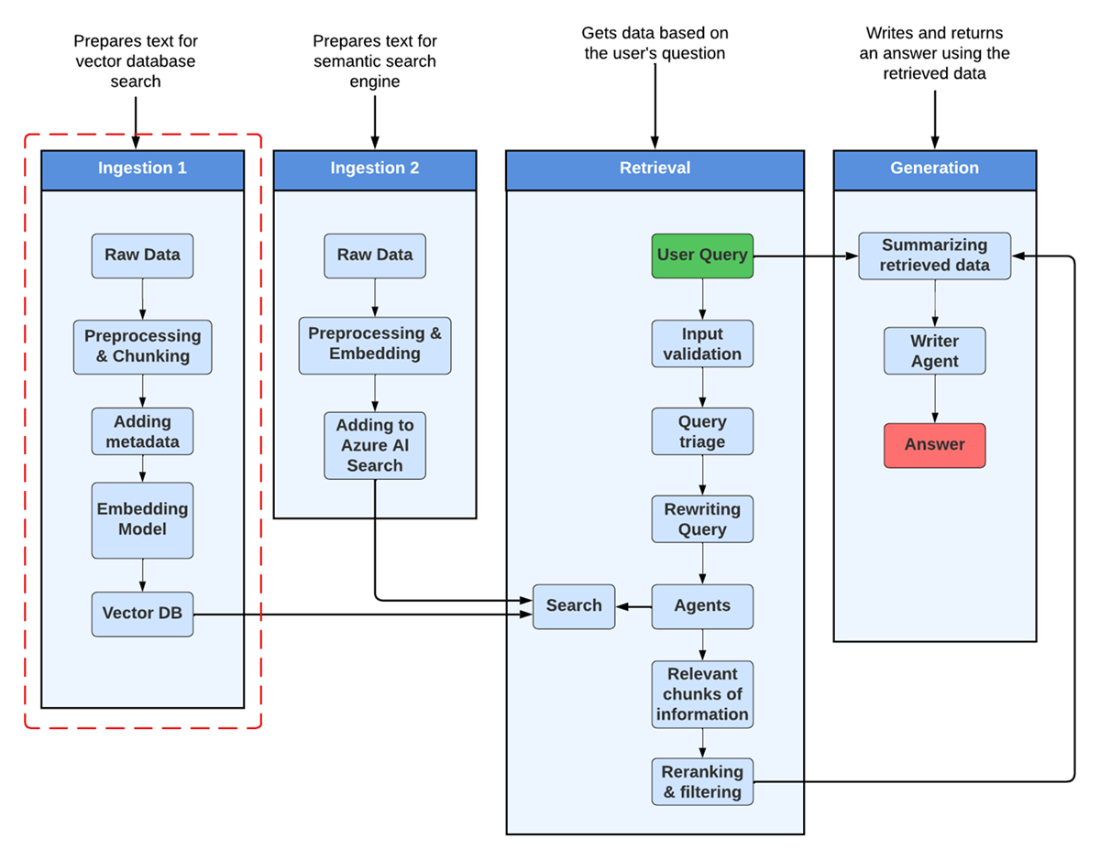
Earlier, in Chapter 1, we looked at the big-picture architecture of a RAG system. Now, as we examine Figure 3.1, you’ll notice it shows the same overall diagram but highlights the ingestion phase. By focusing on this part of the pipeline, we can visualize how selecting and preprocessing your data sets the stage for the entire retrieval and answer-generation process. Before we dive into code, we’ll first break down the conceptual steps involved, ensuring that when you see the code, you’ll already understand what it’s aiming to achieve.
Figure 3.1 Ingestion 1 is the first component of our RAG system