7 Microsoft’s GraphRAG implementation
In Chapter 6, you learned how to extract structured information from legal documents to build a knowledge graph. In this chapter, you will explore a slightly different extraction and processing pipeline using Microsoft’s GraphRAG [Edge et al., 2024] approach. This end-to-end example still constructs a knowledge graph but places greater emphasis on natural language summarization of entities and their relationships. The whole pipeline is visualized in Figure 7.1.
Figure 7.1 Microsoft’s GraphRAG pipeline. Image from [Edge et al., 2024] licensed under CC BY 4.0.
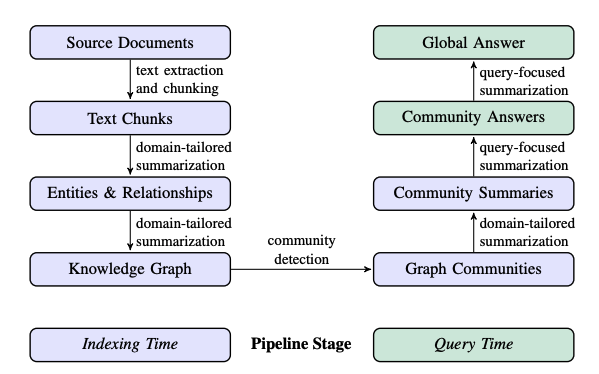
A key innovation of Microsoft’s GraphRAG (MS GraphRAG) is its use of an LLM to build a knowledge graph through a two-stage process. In the first stage, entities and relationships are extracted and summarized from source documents to form the foundation of the knowledge graph, as illustrated in the steps up to the Knowledge Graph in Figure 7.1. What distinguishes MS GraphRAG is that, once the knowledge graph has been constructed, graph communities are detected, and domain-specific summaries are generated for groups of closely related entities. This layered approach transforms fragmented pieces of information from various text chunks into a cohesive and organized representation of information about specified entities, relationships, and communities.