I’ve been writing a blog for a number of years now. Since the beginning, I wanted the website to use clean and simple HTML code. Initially, I wrote articles in HTML by hand, but lately I’ve become a big fan of Markdown—a simple text-based markup language that can be used to produce clean HTML. It’s used by sites such as Stack Overflow and GitHub. But none of the existing Markdown implementations supported what I wanted: I needed an efficient parser that could be extended with custom features and that allowed me to process the document after parsing. That’s why I decided to write my own parser in F#.[1]
1 The Markdown parser I wrote is now a part of F# documentation tools available at http://tpetricek.github.io/FSharp.Formatting/.
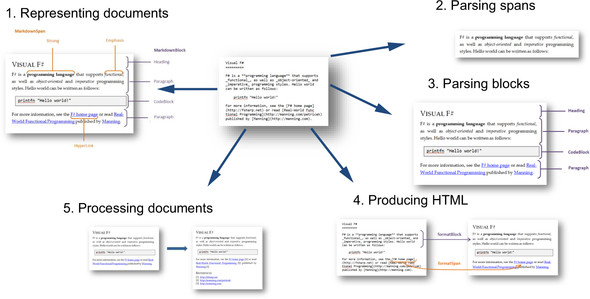
In this chapter, I’ll describe the key elements of the project. You won’t be able to implement a parser for the entire Markdown format in just one chapter, but you’ll learn enough to be able to complete it easily. We’ll first look at the source code of a sample document and then write the document processor in five steps (see figure 1). You’ll see how to represent documents and how to parse inline text spans and blocks. Then you’ll write a translator that turns the document into HTML rendered in a web browser. Finally, we’ll look at how to process documents.