7 Data Modeling in Practice
This chapter covers
- Applying the principals of data modeling to more complex use cases
- Performance improvements that come from using generic labels over specific labels
- Data denormalization techniques to create more efficient graph traversals
- Moving properties to edges to simplify traversals
We’ve walked you through the entire process of building a simple graph application using recursive and path finding traversals in a basic social network. Now we’ll show you how to extend the data model for the recommendation engine and personalization use cases of our app. As we extend the model, we’ll teach you several additional techniques for creating efficient and more complex graph data models. But first, a quick review of the process so far, to help you understand why we need these additional techniques.
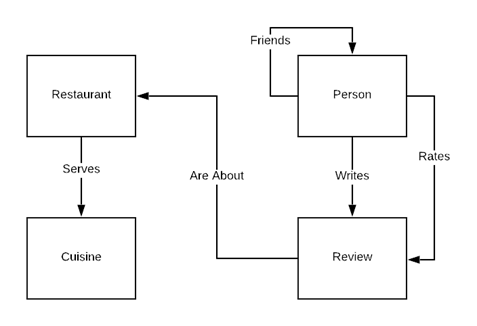
Back in chapter 2, we listed four steps in the data modeling process: defining the problem; creating the conceptual data model; creating the logical data model; and testing the model. We then went through the first two steps for the DiningByFriends app, and came up with the conceptual model shown in Figure 7.1.
Figure 7.1 Conceptual data model showing the entities (boxes) and relationships (arrows) within the DiningByFriends app.