7 Learning and inference at scale
This chapter covers
- Strategies for handling data overload in small systems
- Recognizing graph neural network problems that require scaled resources
- Seven robust techniques for mitigating problems arising from large data
- Scaling graph neural networks and tackling scalability challenges with PyTorch Geometric
For most of our journey through graph neural networks (GNNs), we’ve explained key architectures and methods, but we’ve limited examples to problems of relatively small scale. Our reason for doing so was to allow you to access example code and data readily.
However, real-world problems in deep learning are not often so neatly packaged. One of the major challenges in real-world scenarios is training GNN models when the dataset is large enough to fit in memory or overwhelm the processor [1].
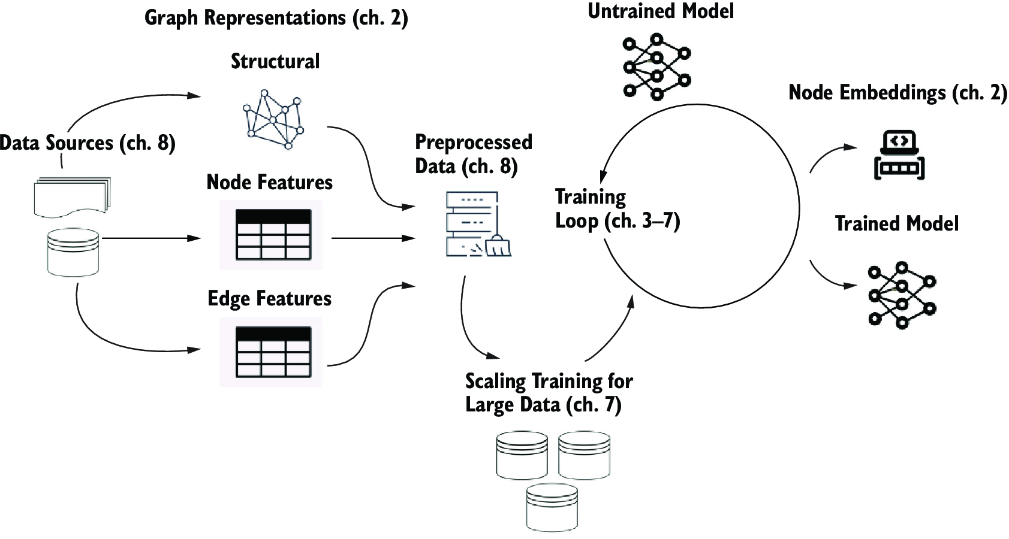
As we explore the challenges of scalability, it’s crucial to have a clear mental model of the GNN training process. Figure 7.1 revisits our familiar visualization of this process. At its core, the training of a GNN revolves around acquiring data from a source, processing this data to extract relevant node and edge features, and then using these features to train a model. As the data grows in size, each of these steps can become increasingly resource-intensive, making necessary the scalable strategies we’ll explore in this chapter.
Figure 7.1 Mental model for the GNN training process. We will focus on scaling our system for large data in this chapter.