chapter eleven
In this chapter
- Understanding the intuition of large language models (LLMs)
- Identifying and preparing LLM training data
- Deeply understanding the operations in training an LLM
- Implementation details and LLM tuning approaches
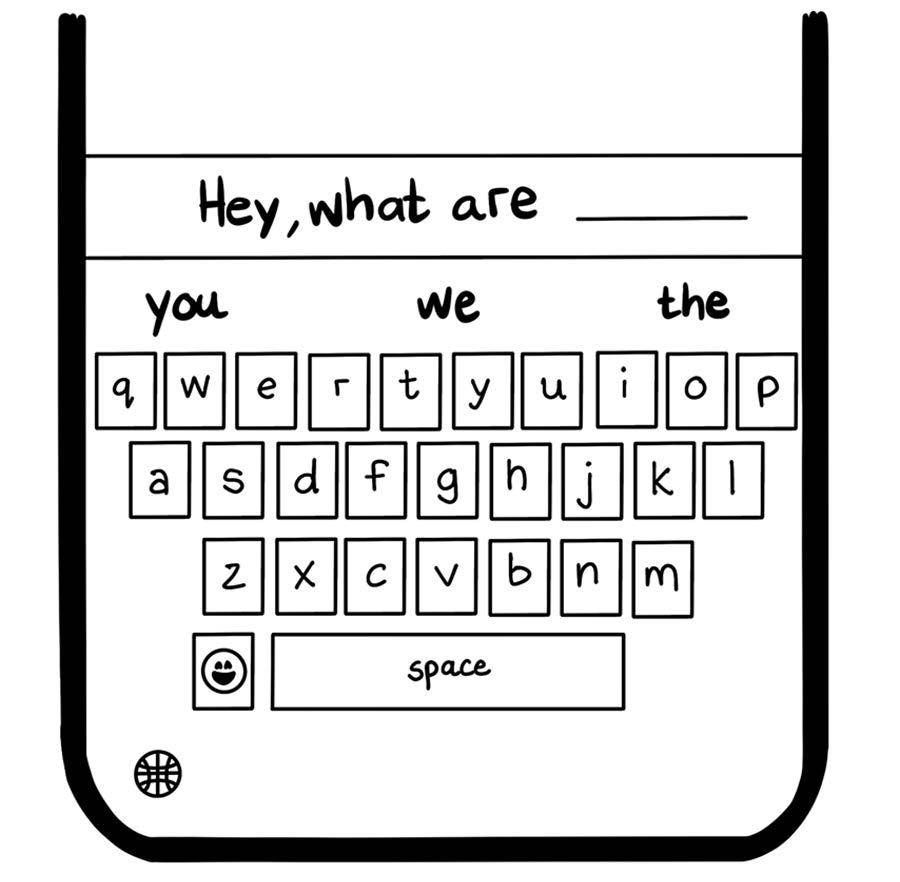
LLMs are machine learning models specialized for natural language processing (NLP) problems such as language generation. Consider the autocomplete feature on your mobile device’s keyboard (figure 11.1). When you type Hey, what are, the keyboard likely predicts that the next word is you, we, or the because those words are the most common ones after that phrase. It makes this choice by scanning a table of probabilities that was trained on commonly available pieces of content. This simple table is a language model.
Figure 11.1 Example of autocomplete as a language model
An LLM is exactly the same idea, with some fundamental upgrades to enable interesting capabilities that come with predicting more than one word at a time: