Chapter 10. K-nearest neighbors

- You learn to build a classification system using the k-nearest neighbors algorithm.
- You learn about feature extraction.
- You learn about regression: predicting a number, like the value of a stock tomorrow, or how much a user will enjoy a movie.
- You learn about the use cases and limitations of k-nearest neighbors.
Look at this fruit. Is it an orange or a grapefruit? Well, I know that grapefruits are generally bigger and redder.
My thought process is something like this: I have a graph in my mind.
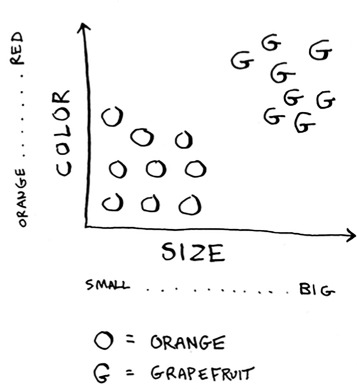
Generally speaking, the bigger, redder fruit are grapefruits. This fruit is big and red, so it’s probably a grapefruit. But what if you get a fruit like this?
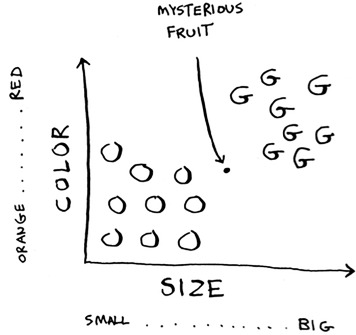
How would you classify this fruit? One way is to look at the neighbors of this spot. Take a look at the three closest neighbors of this spot.
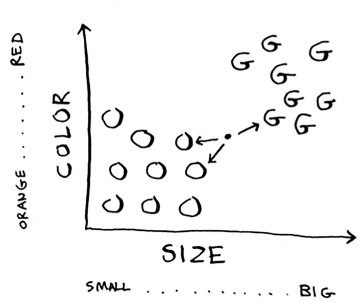
More neighbors are oranges than grapefruit. So this fruit is probably an orange. Congratulations: You just used the k-nearest neighbors (KNN) algorithm for classification! The whole algorithm is pretty simple.

The KNN algorithm is simple but useful! If you’re trying to classify something, you might want to try KNN first. Let’s look at a more real-world example.
Suppose you’re Netflix, and you want to build a movie recommendations system for your users. On a high level, this is similar to the grapefruit problem!
You can plot every user on a graph.