chapter eight
8 Introduction to value-based deep reinforcement learning
This chapter covers
- You’ll understand the inherent challenges of training reinforcement learning agents with non-linear function approximators.
- You’ll create a deep reinforcement learning agent that when trained from scratch with minimal adjustments to hyper-parameters can solve different kinds of problems.
- You’ll identify the advantages and disadvantages of using value-based methods when solving reinforcement learning problems.
Human behavior flows from three main sources: desire, emotion, and knowledge.
— PlatoA philosopher in Classical Greeceand Founder of the Academy in Athens
8.1 The kind of feedback a deep reinforcement learning agent deals with
8.1.1 Deep reinforcement learning deals with sequential feedback
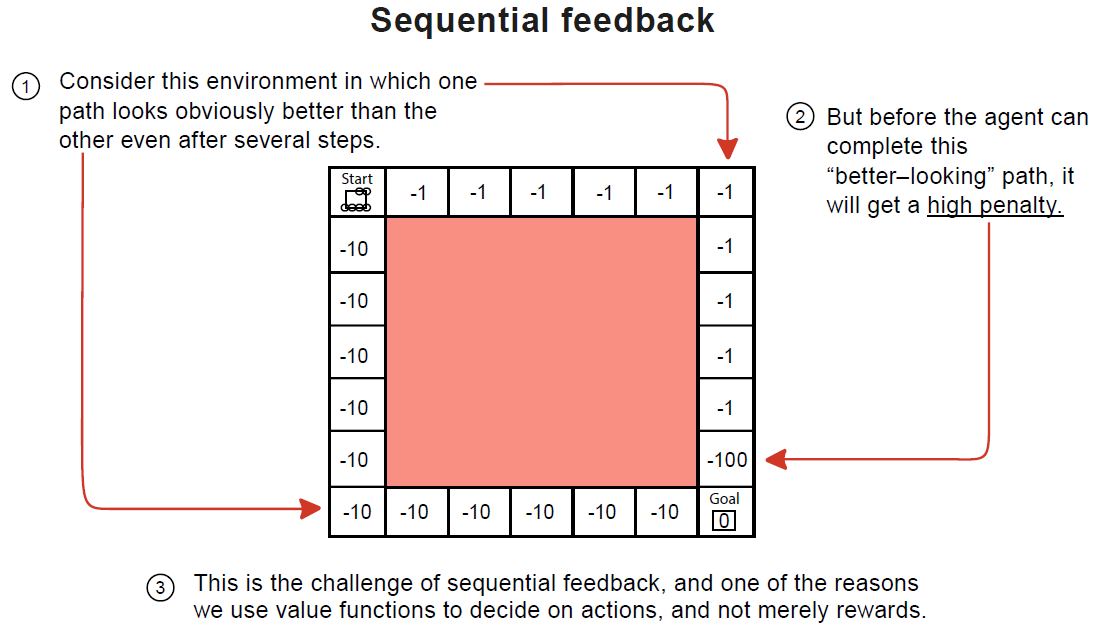
Deep reinforcement learning agents deal with sequential, evaluative and sampled feedback. Up until now, you studied two of the three properties (sequential and evaluative) both in isolation (MDPs is sequential and Bandits is evaluative) and then in interplay ('tabular' reinforcement learning is both sequential and evaluative).
Initially, we examined the issues with sequential feedback in which actions have not only immediate but also long-term consequences. Remember MDPs? Value Iteration? Policy Iteration?
Figure 8.1 Sequential feedback