In this chapter
- parallelization
- data parallelism and task parallelism
- event grouping
“Nine people can’t make a baby in a month.”
—Frederick P. Brooks
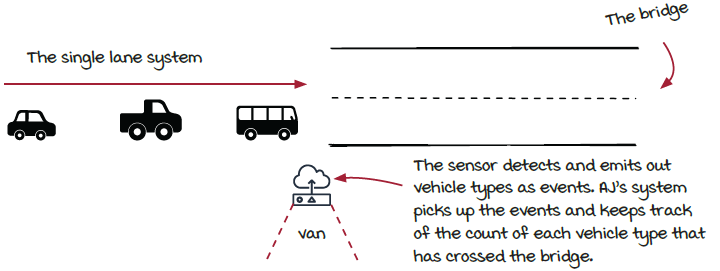
In the previous chapter, AJ and Miranda tackled keeping a real-time count of traffic driving over the bridge using a streaming job. The system she built is fairly limited in processing heavy amounts of traffic. Can you imagine going through a bridge and tollbooth with only one lane during rush hour? Yikes! In this chapter, we are going to learn a basic technique to solve a fundamental challenge in most distributed systems. This challenge is scaling streaming systems to increase throughput of a job or, in other words, process more data.
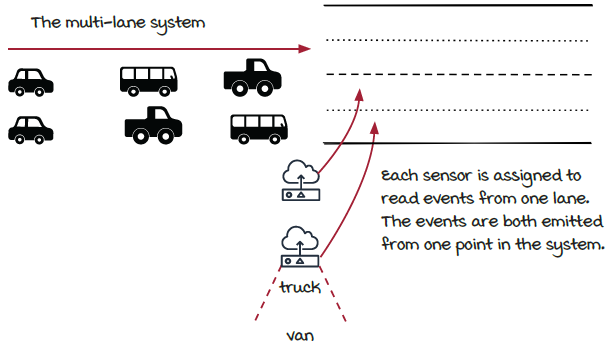
In the previous chapter, AJ tackled keeping a real-time count of traffic driving over the chief’s bridge using a streaming job. Detecting traffic with one sensor emitting traffic events was acceptable for collecting the traffic data. Naturally, the chief wants to make more money, so he opted to build more lanes on the bridge. In essence, he is asking for the streaming job to scale in the number of traffic events it can process at one time.
A typical solution in computer systems to achieve higher throughput is to spread out the calculations onto multiple processes, which is called parallelization.