This chapter covers:
- organizing data processing pipelines via streaming data
- efficient input-output
- parsing data
- manipulating complex data structures
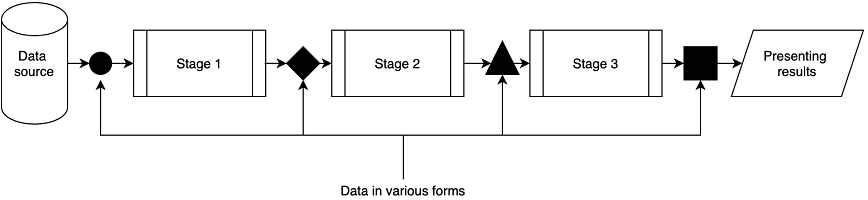
Many applications share a similar structure: they read a data source, transform data to a form suitable for processing, process data somehow, prepare results and present those results to a user. We call this structure a data processing pipeline. The stockquotes project from chapter 3 was a simple example of such an application. In real world applications one needs to take special care to keep performance and memory usage under control.
Figure 14.1 presents a pipeline starting from a data source and ending up at a resulting output. The term pipeline suggests having different stages. We do different things at those stages. At every stage, we have data in some form in the beginning and produce data in some new form as a result.
Figure 14.1. General data processing pipeline
In this chapter, we discuss Haskell tools that allow us to implement data processing pipelines. While particular stages can be very specific, we need to organize them at least. We start with discussing a problem and implementations of streaming as a solution for organizing pipelines and stages.