appendix D Understanding Kafka Streams architecture
In this book, you’ve learned that Kafka Streams is a directed, acyclic graph of processing nodes called a topology. You’ve seen how to add processing nodes to a topology for processing events in a Kafka Topic. But we still need to discuss how Kafka Streams get events into a topology, how the processing occurs, and how processed events are written back to a Kafka topic. We’ll take a deeper look into these questions in this appendix.
D.1 High-level view
Figure D.1 Componetized view of a Kafka Streams application. There are three sections: consuming, processing, and producing.
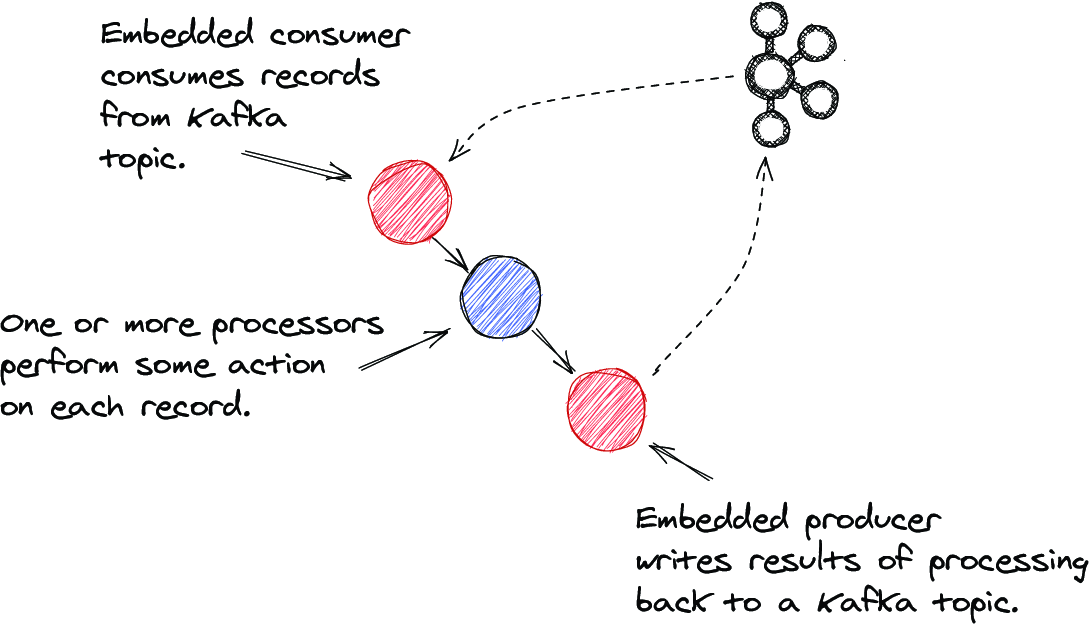
As you can see from the figure, at a high level, we can break up how a Kafka Streams application works into three categories:
- Consuming events from a Kafka topic
- Assigning, distributing, and processing events
- Producing processed events results to a Kafka topic
Given that we’ve already covered the Kafka clients in a previous chapter and that Kafka Streams is an abstraction over them, we won’t get into those details here. Instead, I’ll combine consuming and producing into a more general discussion on clients and then go deeper into Kafka Streams architecture for assigning, distributing, and processing events.