This chapter covers:
- Explaining how the Kafka Broker is the storage layer in the Kafka event streaming platform
- Describing how Kafka brokers handle requests from clients for writing and reading records
- Understanding topics and partitions
- Using JMX metrics to check for a healthy broker
In chapter one, I provided an overall view of the Kafka event streaming platform and the different components that make up the platform. In this chapter, we will focus on the heart of the system, the Kafka broker. The Kafka broker is the server in the Kafka architecture and serves as the storage layer.
In the course of describing the broker behavior in this chapter, we’ll get into some lower-level details. I feel it’s essential to cover them to give you an understanding of how the broker operates. Additionally, some of the things we’ll cover, such as topics and partitions, are essential concepts you’ll need to understand when we get into the chapter on clients. But in practice, as a developer, you won’t have to handle these topics daily.
As the storage layer, the broker is responsible for data management, including retention and replication. Retention is how long the brokers store records. Replication is how brokers make copies of the data for durable storage, meaning if you lose a machine, you won’t lose data.
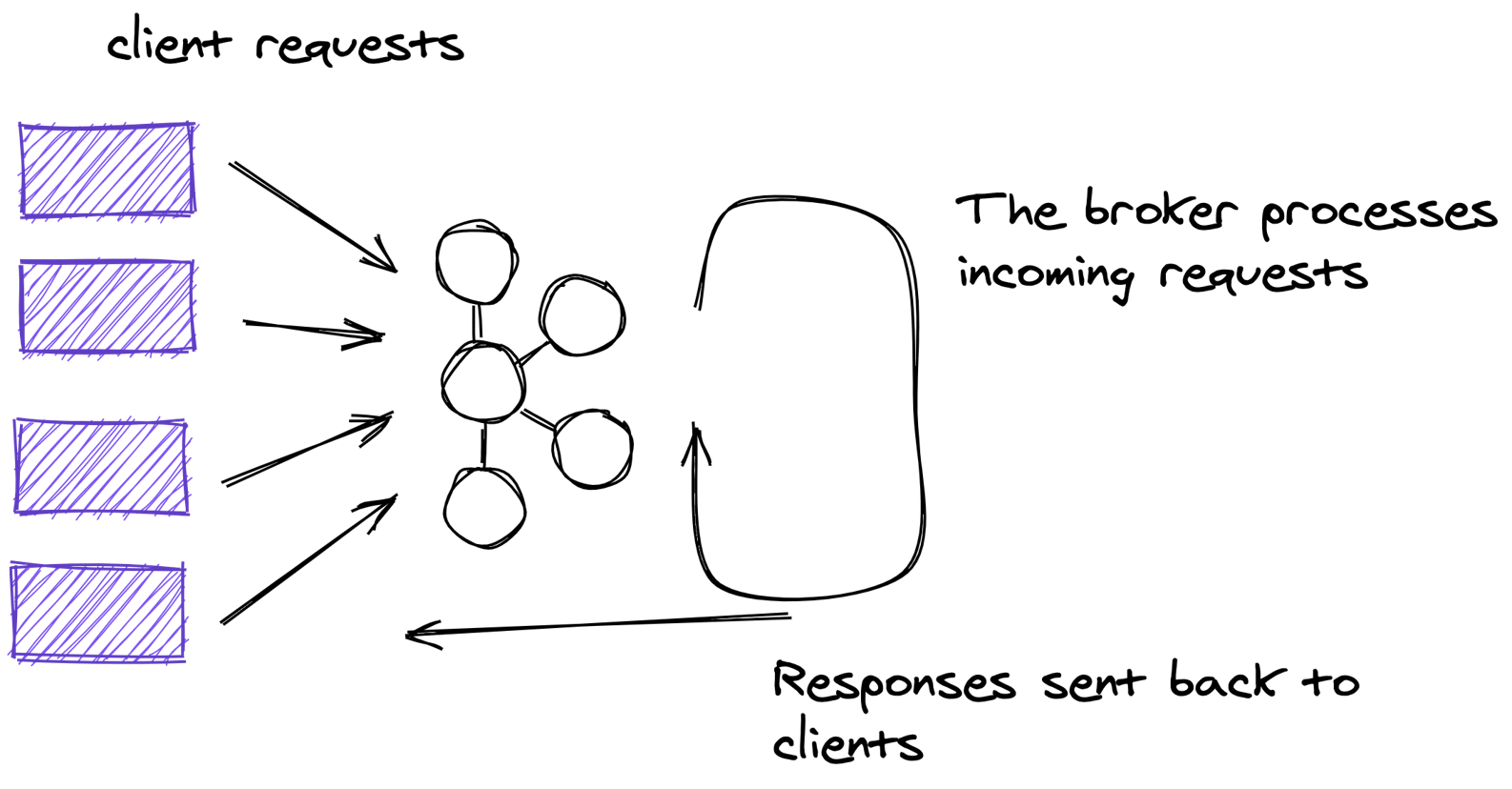
But the broker also handles requests from clients. Here’s an illustration showing the client applications and the brokers:
Figure 2.1. Clients communicating with brokers