6 Building knowledge graphs with large language models
This chapter covers
- Transforming an archive into a knowledge graph
- Graph modeling
- Data normalization and cleansing
- Entity resolution
- Analyzing the intellectual network
In the previous chapter, we discussed extracting complex relational knowledge from unstructured data using state-of-the-art machine learning (ML) technologies, including large language models (LLMs). Specifically, we looked at extracting knowledge from the historical typewritten documents of the Rockefeller Archive Center (RAC). As a brief reminder, these documents contain detailed descriptions of conversations between Rockefeller Foundation (RF) program officers and researchers from a wide range of universities and other institutions. The RF used the information collected during these meetings to decide whether to fund research projects. For a detailed description of the RAC use case and the goals of the project, revisit chapter 5.
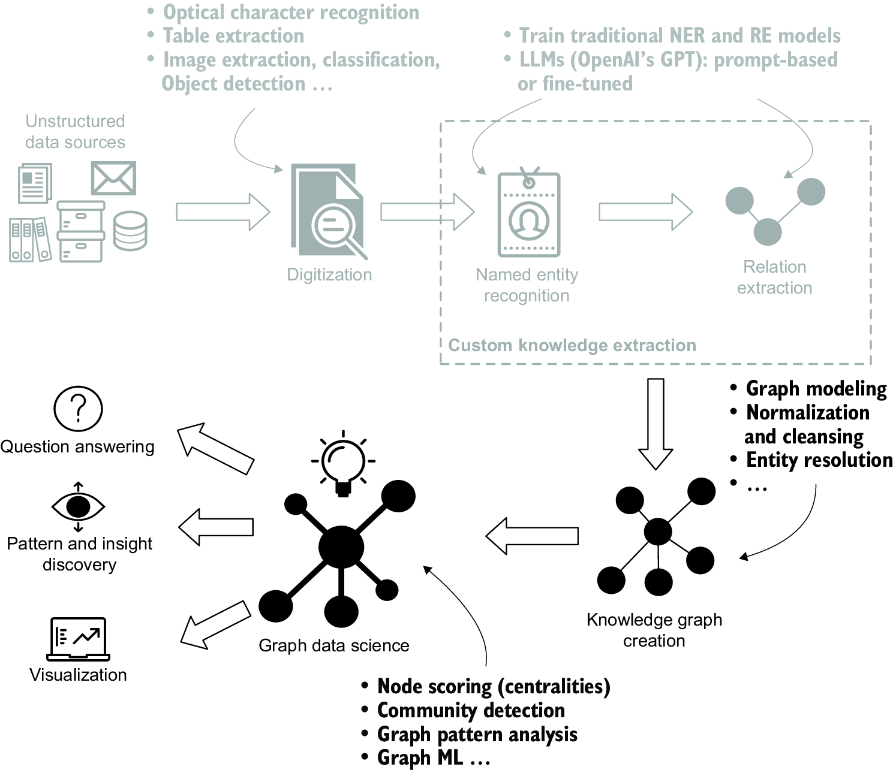
As highlighted by the mental model in figure 6.1, we’ll pick up where we left off: we’ve extracted the knowledge from the textual documents, and now we’ll explore how to transform it into a KG and how to use the KG for the benefit of our organization.
Figure 6.1 Path from domain-specific unstructured textual data toward KG insights. The steps rely on state-of-the-art ML models, such as optical character recognition for document digitization, named entity recognition and relation extraction systems, entity resolution, and GraphML.