Appendix A. The Transformer architecture
To understand how Large Language Models (LLMs) work, it's essential to grasp the "Transformer architecture." This architecture was introduced in 2017 in a paper titled "Attention is All You Need" by Ashish Vaswani, the Google Brain team, and Google Research. The paper is based on principles of attention, encoder-decoder concepts, and requires some foundational knowledge in artificial neural networks, embeddings, and positional encodings.
This appendix explains these concepts to give you a clearer understanding of how LLMs function. It will also help you comprehend the architectural diagram presented in Chapter 1 (Figure 1.3) and below (Figure A.1).
Figure A.1 Diagram from the paper "Attention is all you need", Vaswani et al.
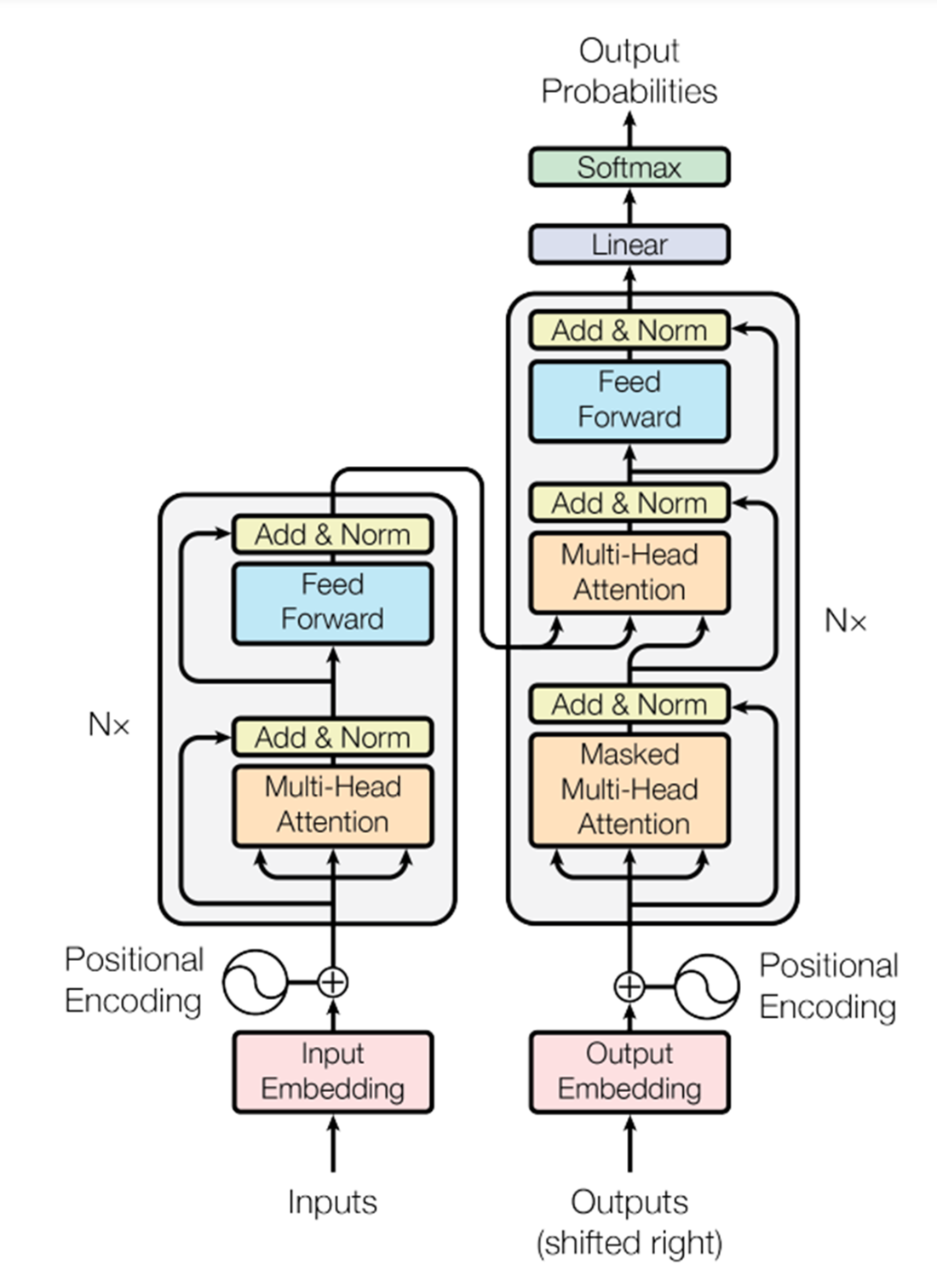
A.1 Artificial Neural Networks fundamentals
Artificial Neural Networks (ANNs) mimic human brain processes. Just like the human brain consists of trillions of interconnected neurons and synapses, ANNs are made up of nodes (similar to neurons) connected by weighted links. These link weights, which are determined during the training of the network, act like the strengths of synapses in the brain, affecting the flow of data. Input values, usually represented as vectors, are multiplied by these weights and pass through the connections to generate the final results.