Appendix A. The Transformer architecture
To understand how Large Language Models (LLMs) work, it's essential to grasp the "Transformer architecture." This architecture was introduced in 2017 in a paper titled "Attention is All You Need" by Ashish Vaswani, the Google Brain team, and Google Research (https://arxiv.org/abs/1706.03762). The paper is based on principles of attention, encoder-decoder concepts, and requires some foundational knowledge in artificial neural networks, embeddings, and positional encodings.
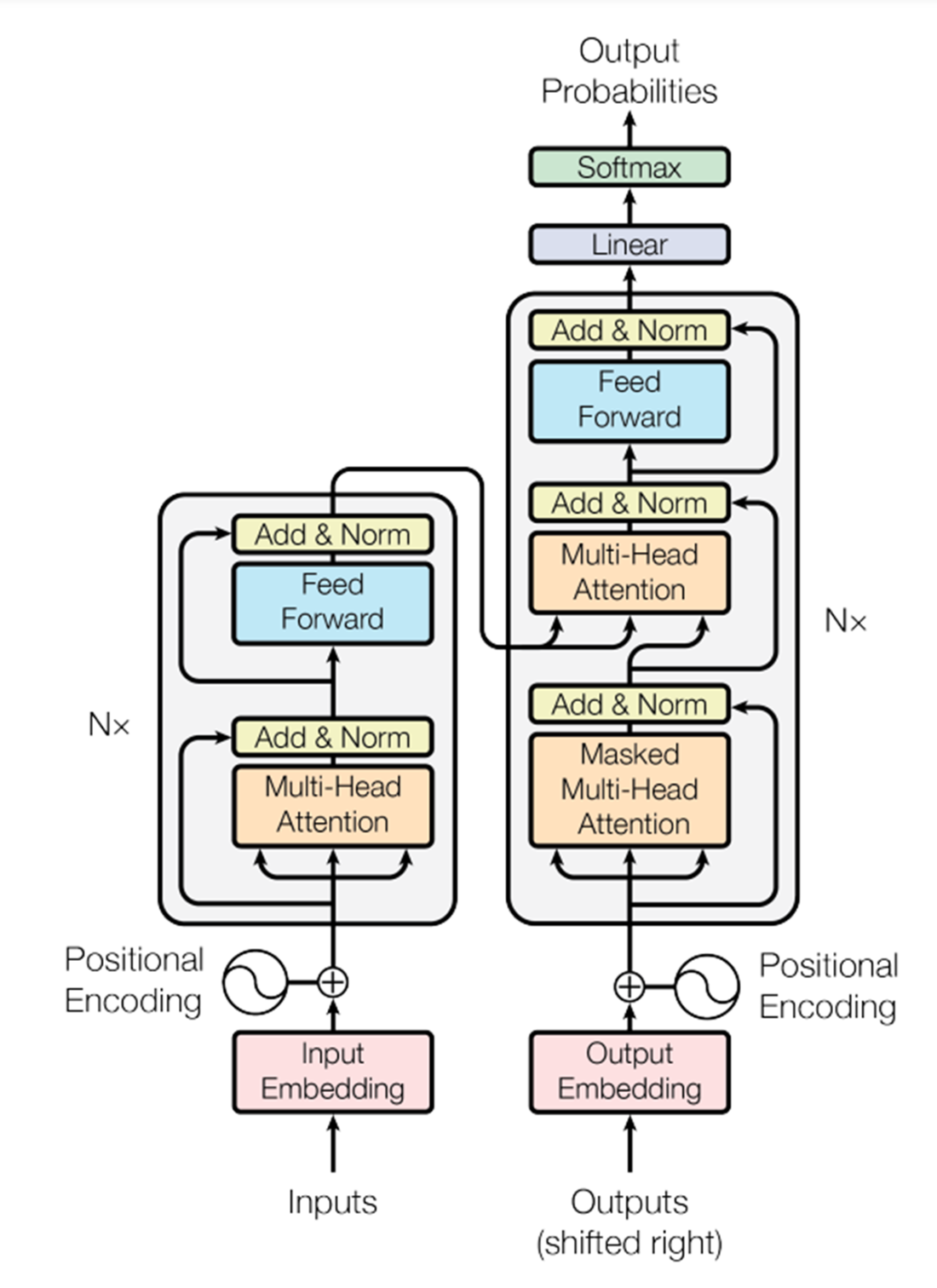
This appendix explains these concepts to give you a clearer understanding of how LLMs function. It will also help you comprehend the architectural diagram presented in Chapter 1 (Figure 1.10) and below (Figure A.1). For a deeper understanding of the Transformer architecture, see Transformers in Action by Nicole Koenigstein or Build a Large Language Model (From Scratch) by Sebastian Raschka, both published by Manning.
Figure A.1 Diagram from the paper "Attention is all you need", Vaswani et al.