This chapter covers
- Building a batch pipeline for model inference using Kubeflow pipelines
- Creating a complete batch inference workflow, from loading data to running model inference
In chapter 4, we established reliable tracking of ML experiments with MLflow and feature management with Feast. However, these tools still require manual intervention to coordinate model training, feature updates, and inference. This is where pipeline orchestration becomes crucial (figure 5.1).
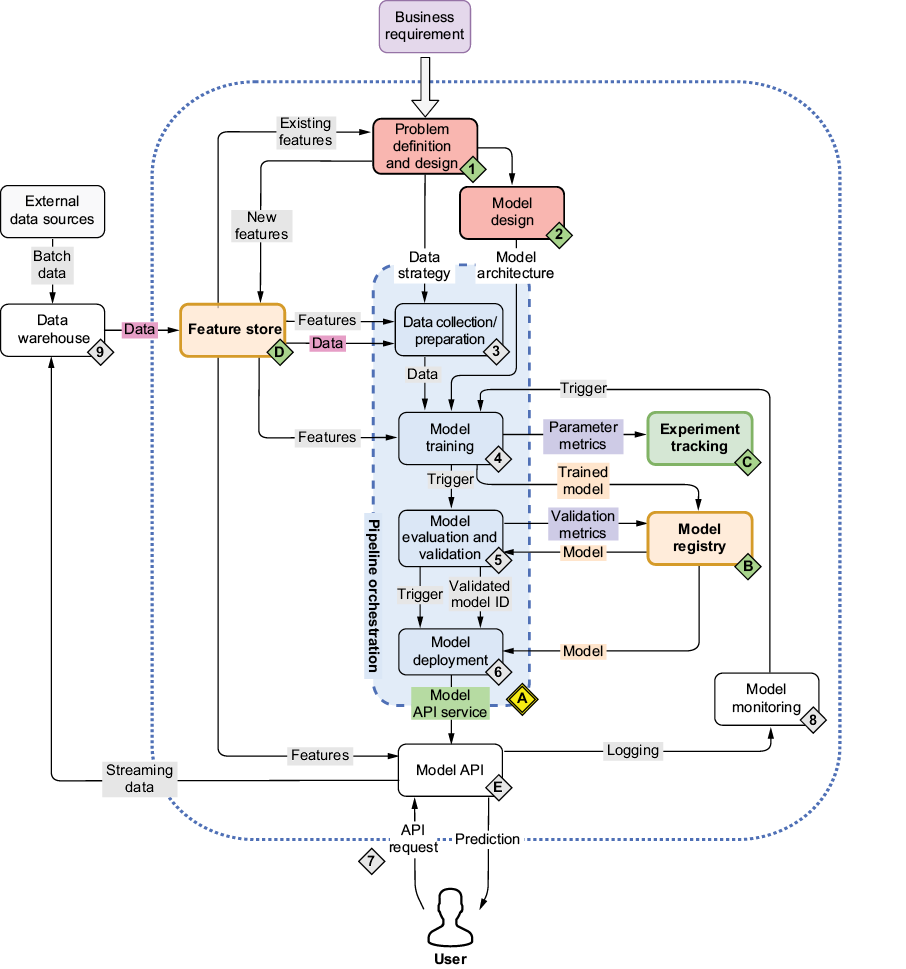
In this chapter, we’ll use Kubeflow Pipelines (KFP) to automate these workflows, making our ML systems more scalable and reproducible. Through a practical income classification example, we’ll see how to turn manual steps into automated, reusable pipeline components. All the code for this chapter is available on GitHub: https://github.com/practical-mlops/chapter-5.
5.1 Kubeflow Pipelines: Task orchestrator
Most ML inference pipelines have a common structure: we need to retrieve data from somewhere (object store, data warehouse, filesystem), preprocess that data, retrieve or load a model, and then perform inference. The inferences are then written to a database or uploaded to some cloud storage. A pipeline needs to run periodically, and we may need to provide some runtime parameters such as date/time, feature table name, and so on. All of this is possible using KFP.