This chapter covers
- Deploying ML models as a service using the BentoML deployment manager
- Tracking data drift using Evidently
After orchestrating ML pipelines in chapter 5, we now face two critical challenges in the ML life cycle: deployment and monitoring. How do we reliably serve our models in production, and how do we ensure that they continue performing well over time?
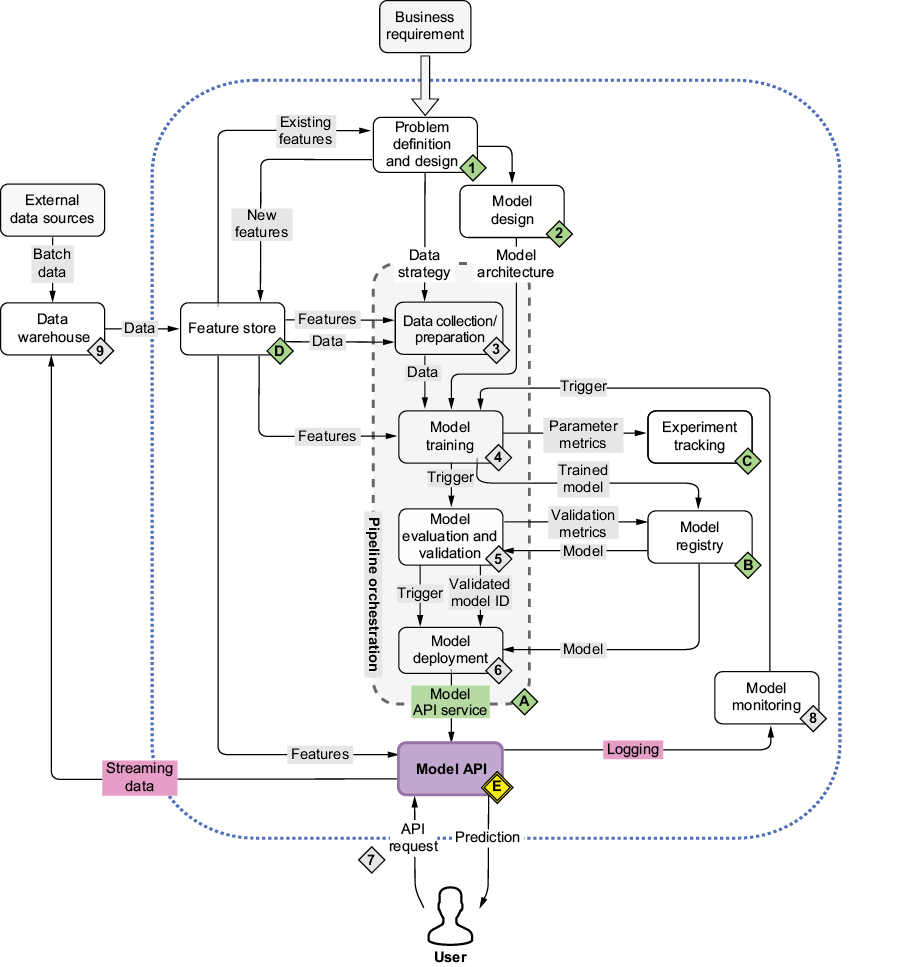
Now we’ll tackle the core challenges of deploying ML models into production—challenges that apply broadly across both traditional ML models and large language models (LLMs). We explore how to efficiently serve models as APIs using BentoML, a powerful platform that simplifies deployment and abstracts away much of the underlying infrastructure complexity (figure 6.1). By automating key parts of the deployment workflow, BentoML allows ML engineers to focus on serving logic rather than setup details.
Figure 6.1 The mental map where we’re now focusing on deploying the model as an API (E)
We also address a common yet critical challenge in production ML systems: data drift. As real-world data distributions evolve, model performance can deteriorate. To address this, we introduce Evidently, a monitoring tool designed to detect and analyze data drift, enabling proactive maintenance of model performance in production environments.