chapter nine
This chapter covers
- Storing and retrieving datasets with Kubernetes PersistentVolumes
- Using MLflow and TensorBoard to track and visualize training
- Understanding the importance of lineage and experiment tracking
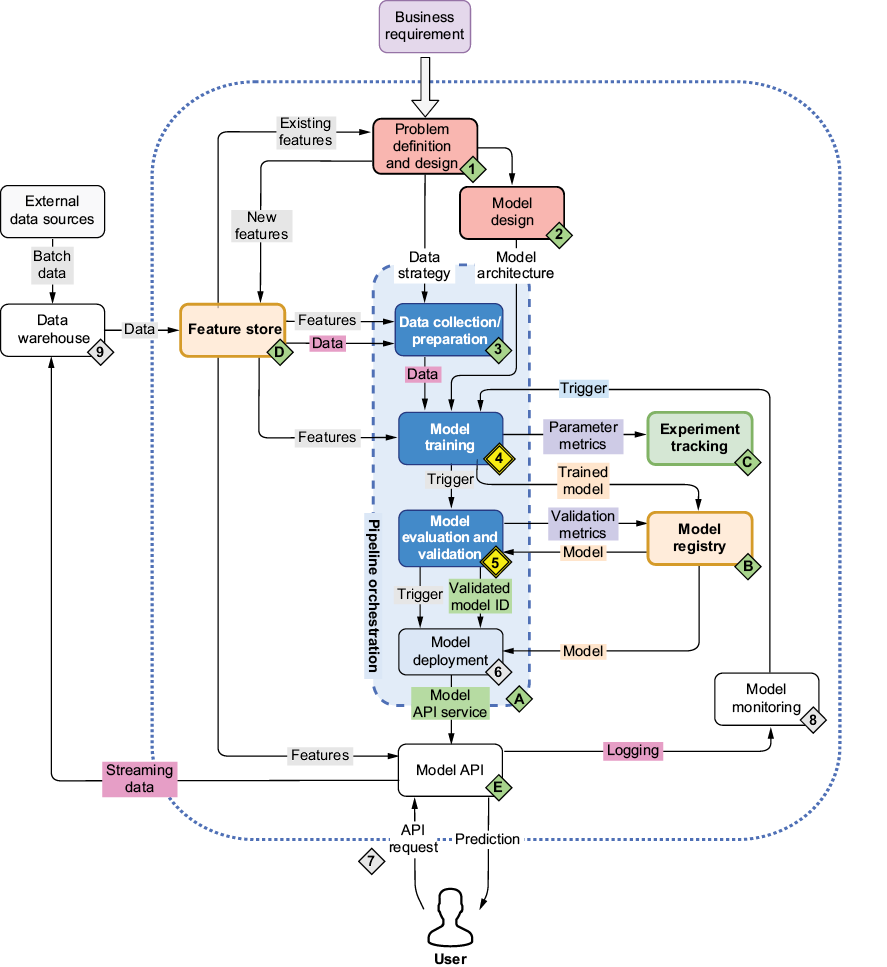
In production ML systems, effective model training extends beyond just algorithms and datasets—it requires robust infrastructure for data management, experiment tracking, and model versioning (figure 9.1). While chapter 8 focused on building basic training pipelines, this chapter tackles the challenges of scaling these pipelines for production use. Through hands-on examples using both our ID card detection and movie recommendation systems, we’ll explore how to manage large datasets efficiently with Kubernetes PersistentVolumes (PVs), track experiments systematically with MLflow and TensorBoard, and maintain clear model lineage for production deployments.
Figure 9.1 The mental map where we continue focusing on the second and third step/component of our pipeline—model training (4) and evaluation (5)