Chapter 4. Working with data
This chapter covers
- Meteor’s default data sources
- The principles of reactive data and computations
- The Session object
- Working with a MongoDB database using Collections
- CRUD operations
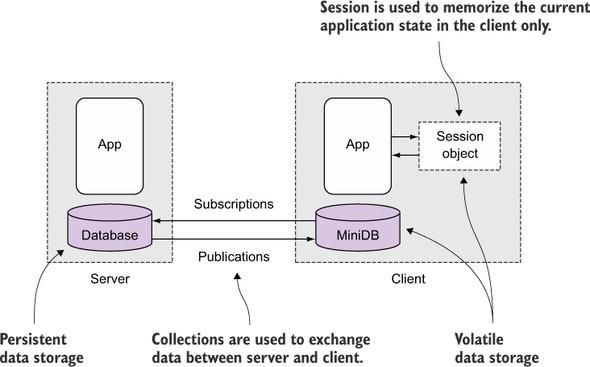
As you saw in chapter 1, Meteor doesn’t rely on a traditional, server-focused architecture. It runs code and processes data on each client as well. To do so, it uses a mini-database to mimic the API of a real database inside the browser. That means you can access data in the same manner, regardless of whether you’re making a database lookup or accessing the results of a query on the browser.
All data that’s available only in a single client will obviously be lost once the client disconnects and hasn’t sent its updates back to a central server. Meteor will take care of persisting data automatically by synchronizing client and server state.
Some information is relevant for only a single client, such as state information, which tabs have been clicked, or which value was selected from a drop-down list. Information that’s relevant only to an ongoing user session doesn’t need to be stored on the central server and doesn’t get synchronized. Figure 4.1 illustrates the general architecture. At the end of this chapter, you’ll be able use Collections for data inside databases and Sessions for client-only information.