The pandas DataFrame is a two-dimensional table of data with rows and columns. As with a Series, pandas assigns an index label and an index position to each DataFrame row. Pandas also assigns a label and a position to each column. The DataFrame is two-dimensional because it requires two points of reference—a row and a column—to isolate a value from the data set. Figure 4.1 displays a visual example of a pandas DataFrame.
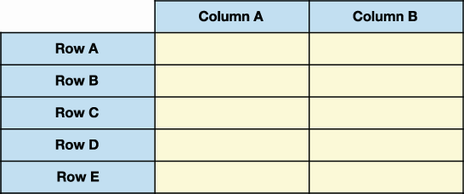
The DataFrame is the workhorse of the pandas library and the data structure you’ll be working with most on a daily basis, so we’ll be spending the remainder of this book exploring its vast features.
As always, let’s spin up a new Jupyter Notebook and import pandas. We also need the NumPy library, which we’ll use in section 4.1.2 to generate random data. NumPy is usually assigned the alias np:
In [1] import pandas as pd
import numpy as np