7 OpenMP that performs
This chapter covers
- Planning and designing a correct and performant OpenMP program
- Quickly writing loop-level OpenMP for modest parallelism
- Detecting correctness problems and improving robustness
- Fixing performance issues with OpenMP
- Writing scalable OpenMP for high performance
7.1 OpenMP introduction
7.2 Typical OpenMP use cases: Loop-level, High-level, and MPI+OpenMP
OpenMP has three specific use scenarios. These are for the needs of three different types of users. The first decision is which use scenario is appropriate for your situation. The strategy and techniques vary for these cases and will be discussed separately. The use cases include loop-level OpenMP, high-level OpenMP, and the use of OpenMP to enhance an MPI implementation. In the following sections, we will elaborate on each of these use cases, when to use them, why to use them, and how to use them. Figure 7.4 shows the recommended material to be carefully read for each of the use cases.
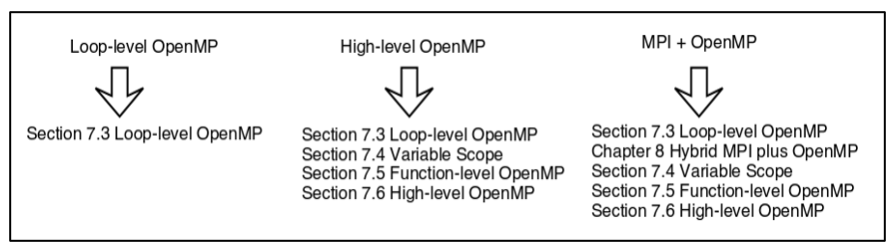
Figure 7.4 The recommended reading for each of the use cases depends on the use case for your application.
7.2.1 Loop-level OpenMP for quick parallelization
A standard use case for loop-level OpenMP is when your application only needs a modest speedup and has plenty of memory resources. By this we mean because it’s requirements can be satisfied by the memory on a single hardware node. In this use case it may be sufficient to use loop-level OpenMP. Summarizing the application characteristics of loop-level OpenMP
· Modest parallelism
· Has plenty of memory resources (low memory requirements)
· Expensive part of calculation is in just a few for loops or do loops
Loop-level OpenMP is used in this case because it takes a low amount of effort and can be done quickly. With separate parallel for pragmas, the issue of thread race conditions are much reduced.
By placing OpenMP parallel for pragmas or parallel do directives in front of key loops, the parallelism of the loop can be easily achieved. Even when the end goal is a more efficient implementation, this loop-level approach is often the first step when trying to introduce thread parallelism to an application. If your use case requires only modest speedup, go to section 7.3 for examples of this approach.
7.2.2 High-level OpenMP for better parallel performance
Now we discuss a different scenario, high-level OpenMP, where higher performance is desired. Our high-level OpenMP design has a radical difference from the strategies of standard, loop-level OpenMP. Standard OpenMP starts from the bottom-up and applies the parallelism constructs at the loop-level. Our high-level OpenMP approach takes a whole system view to the design with a top-down approach that addresses the memory system, the system kernel, and the hardware. The OpenMP language does not change, but the method of its use does. The end result is that we eliminate much of the thread startup costs and the costs of synchronization that hobble the scalability of loop-level OpenMP.
If you need to extract every last bit of performance out of your application, then our high-level OpenMP is for you. Begin by learning loop-level OpenMP in section 7.3 as a starting point for your application. Then you will need to gain a deeper understanding of OpenMP variable scope from sections 7.4 and 7.5. Finally, dive into section 7.6 for a look at how the diametrically opposite approach of high-level OpenMP from the loop-level approach results in better performance. In that section we’ll first look at the implementation model and a step-by-step method to reach the desired structure. This will be followed by detailed examples of implementations for high-level OpenMP.
7.2.3 MPI plus OpenMP for extreme scalability
We can also use OpenMP to supplement distributed memory parallelism (discussed in chapter 8 on MPI). The basic idea of using OpenMP on a small subset of processes adds another level of parallel implementation that helps for extreme scaling. This could be within the node, or better yet, the set of processors which share uniformly quick access to shared-memory, commonly referred to as a non-uniform memory access (NUMA) region. NUMA regions were first discussed in section 7.1.1 in OpenMP concepts as an additional consideration for performance optimization. By using threading only within one memory region where all memory accesses have the same cost, some of the complexity and performance traps of OpenMP are avoided. In a more modest hybrid implementation, OpenMP may just be used to harness the two to four hyperthreads for each processor.
We’ll discuss hybrid MPI + OpenMP in chapter 8, after the basics of MPI are covered. For the OpenMP skills needed for this hybrid approach with small thread counts, learning the loop-level OpenMP techniques in section 7.3 is sufficient. Then moving incrementally to a more efficient and scalable OpenMP implementation allows more and more threads to replace MPI ranks. This requires at least some of the steps on the path to high-level OpenMP presented in section 7.6.
Now that you know what sections are important for your application’s use case, let’s jump into the gory details of how to make each strategy work.