chapter seven
- You’ll gain an understanding of what similarity and its cousin, distance, are.
- You’ll look at how to calculate similarity between sets of items.
- With similarity functions, you’ll measure how alike two users are, using the ratings they’ve given to content.
- It sometimes helps to group users, so you’ll do that using the k-means clustering algorithm.
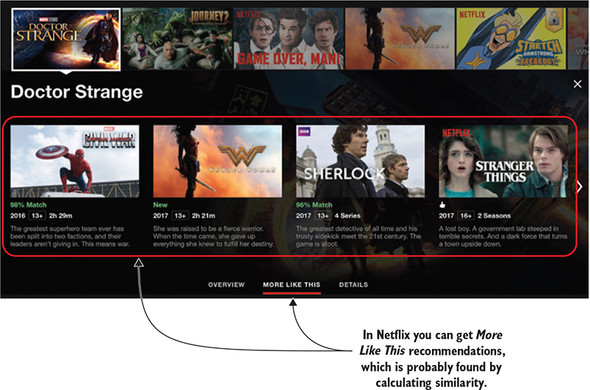
Chapter 6 described non-personalized recommendations and the association rules. Association rules are a way to connect content without looking at the item or the users who consumed them. Personalized recommendations, however, almost always contain calculations of similarity. An example of such recommendations could be Netflix’s More Like This recommendation shown in figure 7.1, where it uses an algorithm to find similar content.