Chapter 5. Message exchange patterns
Chapters 2 and 3 looked at patterns that can help you build services and their interfaces, like Edge Component and Service Instance. Chapter 4 covered ways of protecting and monitoring your services. Chapter 5 is the first of three that covers the different aspects of service interactions. After all, getting services to interact and enable business processes was the reason for using SOA to begin with.
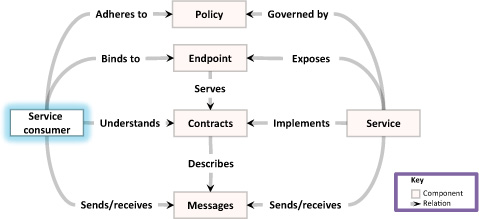
As figure 5.1 illustrates, this chapter’s focus is on the interaction of services with their “customers”—the service consumers. A service consumer is any component or piece of code that interacts with a service. The patterns in this chapter deal with the basics—the message exchange patterns. Chapter 6 looks at service consumers and chapter 7 takes a look at patterns related to service composition and integration.
Figure 5.1. This chapter focuses on connecting services with user interfaces. It’s the first chapter in this book that takes a look at the service consumers.
The SOA definition in chapter 1 says that “each service exposes processes and behavior through contracts, which are composed of messages at discoverable addresses.” This makes service interaction very simple—you just send a message in and get a message back, right? Why do we need a whole chapter, or even two, on service interactions?
The Request/Reply pattern, illustrated in figure 5.3, is the most basic interaction pattern, so there aren’t any special components needed to make it happen. What you do need is a piece of logic that accepts a request, processes it synchronously, and returns a reply or a result. One thing to pay attention to is that both the request and reply messages belong to the contract of the service and not the service consumer (which is a common error for SOA novices).
The Request/Reply pattern is a simple pattern that connects a service consumer with the service that it wants to interact with. As a basic pattern, it doesn’t solve a lot of quality attribute concerns, except for providing the functionality needed (getting the consumer and the service to interact).
Synchronous communication, as described in the Request/Reply pattern (in the previous section), is very important, but it isn’t enough. The synchronous nature of Request/Reply means that the service consumer needs to sit and wait for the service to finish processing the request before the consumer can continue with whatever it was doing. There are situations where the service consumer doesn’t want or can’t afford to wait but is still interested in getting a reply when it’s available.
The idea behind the Request/Reaction pattern, illustrated in figure 5.5, is to have two distinct interactions between the service consumer and the service. The first interaction sends the request to the server, which may return an acknowledgment, a ticket, or an estimate for finishing a job to the consumer. Once the processing is complete, the service has to initiate an interaction with the service consumer and send it the reply or reaction.
Let’s look at the Delays service mentioned in the problem description. Figure 5.11 shows that now the Airports, Weather, and Operational Picture services push their changes to the Delays service instead of the other way around. This has a positive effect on network traffic, because the Delays service no longer has to worry about missing an important change in the three services it monitors. Also note that applying the Inversion of Communications pattern does not mean you have to move all your interactions to events. In this example, the Delays service still has Request/Reply interactions with the Schedules and Reservations services. If the Delays service identifies a delay, it can try to reserve places on later flights for people who would miss their connections.
Inversion of Communications is about implementing EDA on top of SOA. Up to now, we’ve looked at the simple side of that, which involves handling sporadic or isolated events. But a very strong concept that EDA defines is event streams. This means you don’t look at each event on its own, but rather at a chain of related events over time. Event streams can give you both trends and a historical perspective. Used well, this can give you real-time business intelligence and business-activity monitoring. The Aggregated Reporting pattern discussed in chapter 7 shows an application of this capability.
The interaction in figure 5.14 has the service consumer and services controlling the interaction internally. One good way to do this is to use the Workflodize pattern (discussed in chapter 2) so that each service has an internal workflow that follows the sequence and different paths of the interaction. Another pattern related to the Saga pattern is the Reservation pattern (see chapter 6).
Another message type that’s important for the Saga pattern is the failure message. When you have a simple point-to-point interaction between services, the reply or reaction that a called service sends is enough to convey the notion of a problem. The calling service consumer, which understands the service’s contract, can understand that something is amiss and act accordingly. When you implement the Saga pattern, however, you may have more than two parties involved, and you also have a coordinator. The coordinator isn’t as business-aware as the service’s business logic, but it does define control messages in order to understand the status of the interactions.
One distinct characteristic of all the patterns in this chapter is that none of them are new. All the interaction patterns predate SOA by many years. Nevertheless, I’ve spent more than 30 pages discussing them with you, instead of just pointing you to Hohpe and Woolf’s excellent Enterprise Integration Patterns book, which covers these patterns as well. The reason for this is that although these patterns seem relatively simple and well known, each has some aspects that makes them a little complicated when you try to implement them and adhere to SOA principles:
The next two chapters will look at less basic interaction patterns. Some of them are complementary to the patterns discussed here, such as the Reservation pattern in chapter 6, which complements the Saga pattern, or the Aggregated Reporting pattern in chapter 7 that uses the Inversion of Communications pattern. The other patterns we’ll look at have to do with aspects of interactions and aggregations beyond the underlying message exchange patterns, such as the Composite Front End pattern in chapter 6.
Google Data APIs, http://code.google.com/apis/gdata/overview.html. Google’s Google Data Protocol (GData) is an example of a document-centric protocol for interacting with services.
Matt Welsh, “SEDA: An Architecture for Highly Concurrent Server Applications,” www.eecs.harvard.edu/~mdw/proj/seda/. Combining the Inversion of Communications pattern with the Parallel Pipelines pattern gives an SOA implementation of SEDA.