This chapter covers
- How RAG works
- Using tooling to create a basic RAG setup
- Integrating vector databases into a RAG setup
As we learned in the previous chapter, one of the challenges of working with large language models (LLMs) is that they lack visibility of our context. In the second part of this book, we saw different ways in which we can arrange our prompts to help provide small insights into our context. However, these types of prompts are only useful before the lack of extra context leads to less valuable responses. Therefore, to increase the value of an LLM’s response, we need to place more contextual detail into our prompt. In this chapter, we’ll explore how to do this through retrieval-augmented generation, or RAG. We’ll learn how RAG works, why it’s beneficial, and how it’s not a big jump from prompt engineering to building our own RAG framework examples to establish our understanding of how they can help us in a testing context.
11.1 Extending prompts with RAG
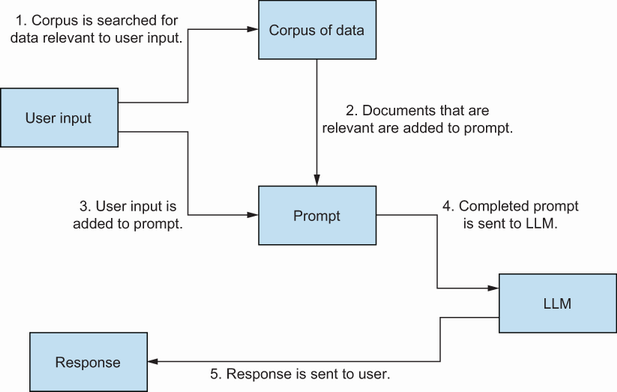
To recap, RAG is an approach to improving the quality of an LLM’s response by combining existing corpus of data with a prompt. Although this broadly explains how RAG works, we need to dig a little deeper to better grasp how this combination of data is achieved. The process of a RAG system is relatively straightforward and can be summarized as shown in figure 11.1.
Figure 11.1 A visualization of how a basic RAG system works