part two
Ingestion is a fancy name for putting the data into the system . I agree with you: it sounds a little too much like digestion and may, at first, scare you.
Nevertheless, don’t be fooled by the apparent small size of this part--four chapters. These chapters are crucial to starting your big data journey, as they really explain how Spark will digest your data, from files to streams. Figure 1 shows the topics that these chapters focus on.
Overall process for ingestion explained over the next four chapters, starting with ingestion from files, then databases, systems, and streams
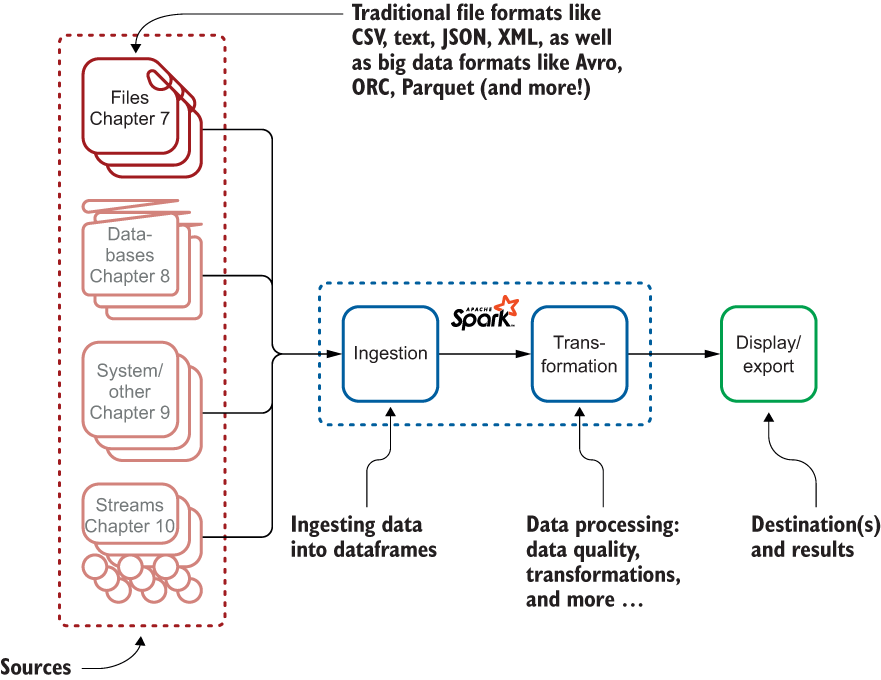
Chapter 7 focuses on ingestion of files. These files can be not only the well-known types such as CSV, text, JSON, and XML, but also the new generation of file formats that have appeared for big data. You will learn why, as well as more about Avro, ORC, and Parquet. Each file format has its own example.