One of the most important things we take into consideration when managing data is to keep accurate data. We don’t want specific execution scenarios to end up with wrong or inconsistent data. Let me give you an example. Suppose you implement an application used to share money—an electronic wallet. In this application, a user has accounts where they store their money. You implement a functionality to allow a user to transfer money from one account to another. Considering a simplistic implementation for our example, this implies two steps (figure 13.1):
Figure 13.1 An example of a use case. When transferring money from one account to another account, the app executes two operations: it subtracts the transferred money from the first account and adds it to the second account. We’ll implement this use case, and we need to make sure its execution won’t generate inconsistencies in data.
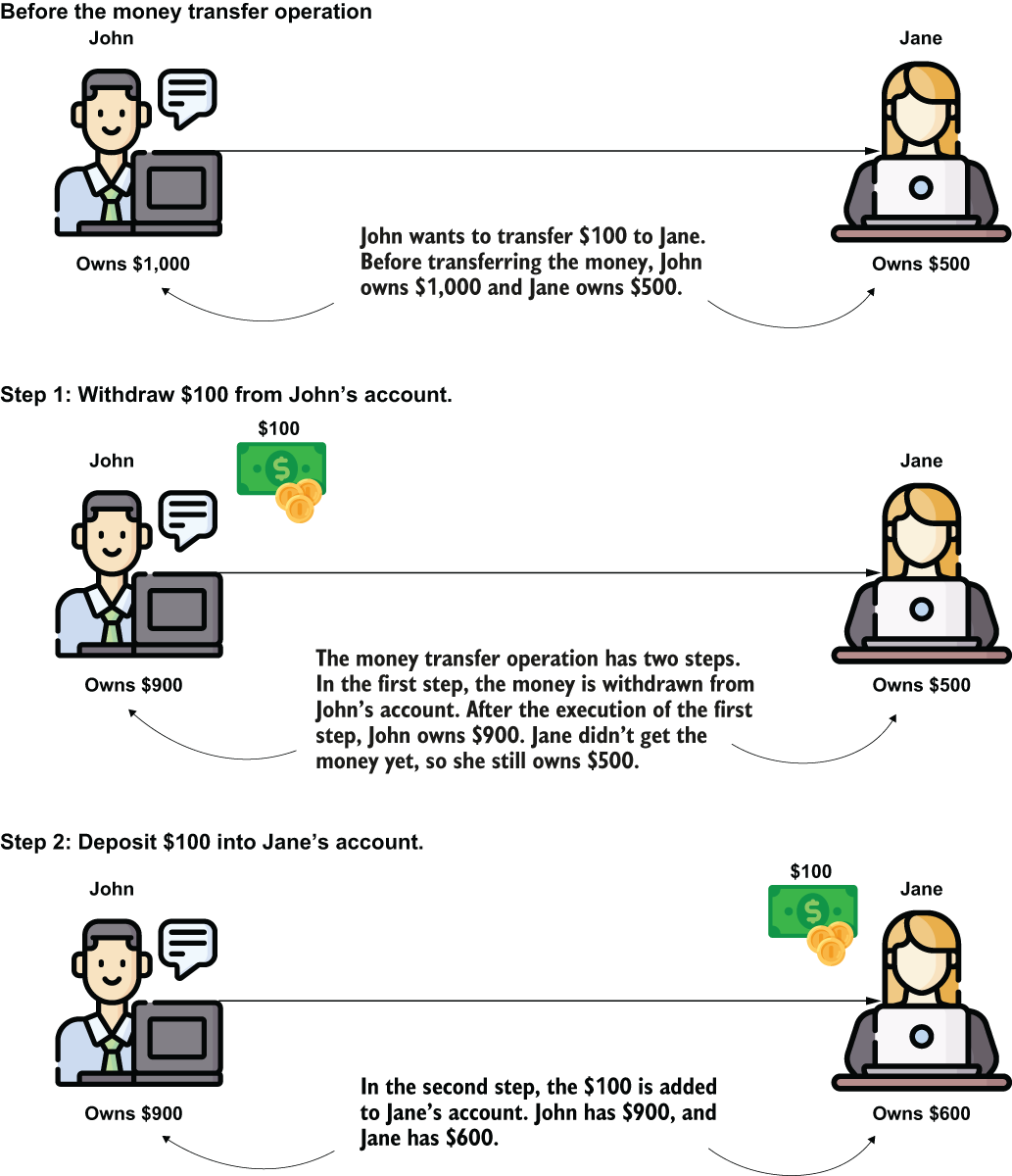
Both these steps are operations that change data (mutable data operations), and both operations need to be successful to execute the money transfer correctly. But what if the second step encounters a problem and can’t complete? If the first finished, but step 2 couldn’t complete, the data becomes inconsistent.