Chapter 6. Storing the analyzed or collected data
This chapter covers
- Understanding why we need to store the data
- Learning what to store
- Choosing your storage solution
Up to this point we have spent time discussing the architecture and the algorithms commonly used in stream-processing applications. This chapter focuses on what to do with the data after you have processed it. Our focus will be less on the performance of any persistent store we use and more on how to choose a persistent store if one is needed for your application.
First let’s recap where we are in the overall architecture. Figure 6.1 shows our over-arching architecture with the focus of this chapter highlighted.
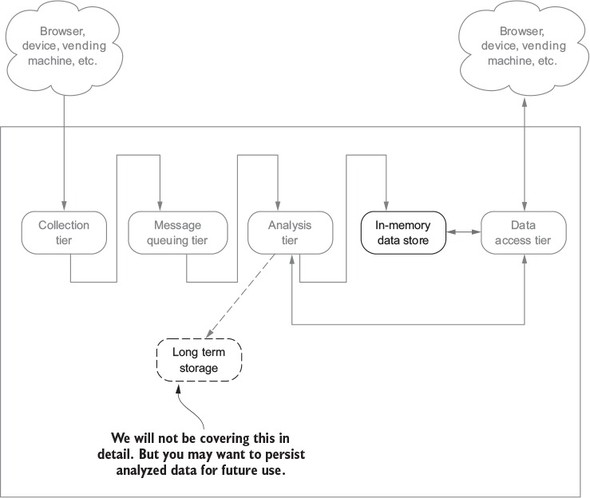
We’ll talk about the storage options from a streaming perspective, the key attributes of the most popular products, and things to consider when you use one. To set the stage, let’s begin with the four options we have when our analysis is done and the data is ready to be consumed. We can do any of the following:
- Analyze and discard the data
- Analyze and push the data back into the streaming platform
- Analyze and store the data for real-time usage
- Analyze and store the data for batch/offline access