concept function in category dask

This is an excerpt from Manning's book Data Science with Python and Dask.
The first thing that sets Dask apart from the competition is that it is written and implemented entirely in Python, and its collection APIs natively scale NumPy, Pandas, and scikit-learn. This doesn’t mean that Dask merely mirrors common operations and patterns that NumPy and Pandas users will find familiar; it means that the underlying objects used by Dask are corresponding objects from each respective library. A Dask DataFrame is made up of many smaller Pandas DataFrames, a Dask Array is made up of many smaller NumPy Arrays, and so forth. Each of the smaller underlying objects, called chunks or partitions, can be shipped from machine to machine within a cluster, or queued up and worked on one piece at a time locally. We will cover this process much more in depth later, but the approach of breaking up medium and large datasets into smaller pieces and managing the parallel execution of functions over those pieces is fundamentally how Dask is able to gracefully handle datasets that would be too large to work with otherwise. The practical result of using these objects to underpin Dask’s distributed collections is that many of the functions, attributes, and methods that Pandas and NumPy users will already be familiar with are syntactically equivalent in Dask. This design choice makes transitioning from working with small datasets to medium and large datasets very easy for experienced Pandas, NumPy, and scikit-learn users. Rather than learning new syntax, transitioning data scientists can focus on the most important aspect of learning about scalable computing: writing code that’s robust, performant, and optimized for parallelism. Fortunately, Dask does a lot of the heavy lifting for common use cases, but throughout the book we’ll examine some best practices and pitfalls that will enable you to use Dask to its fullest extent.
This particular dataset is a plain text file. You can open it with any text editor and start to make sense of the layout of the file. The Bag API offers a few convenience methods for reading text files. In addition to plain text, the Bag API is also equipped to read files in the Apache Avro format, which is a popular binary format for JSON data and is usually denoted by a file ending in .avro. The function used to read plain text files is
read_text, and has only a few parameters. In its simplest form, all it needs is a filename. If you want to read multiple files into one Bag, you can alternatively pass a list of filenames or a string with a wildcard (such as *.txt). In this instance, all the files in the list of filenames should have the same kind of information; for example, log data collected over time where one file represents a single day of logged events. Theread_textfunction also natively supports most compression schemes (such as GZip and BZip), so you can leave the data compressed on disk. Leaving your data compressed can, in some cases, offer significant performance gains by reducing the load on your machine’s input/output subsystem, so it’s generally a good idea. Let’s take a look at what theread_textfunction will produce.
Now that we have a list containing all the byte positions of the reviews, we need to create some instructions to transform the list of addresses into a list of actual reviews. To do that, we’ll need to create a function that takes a starting position and a number of bytes as input, reads the file at the specified byte location, and returns a parsed review object. Because there are thousands of reviews to be parsed, we can speed up this process using Dask. Figure 9.6 demonstrates how we can divide up the work across multiple workers.
Figure 9.6 Mapping the parsing code to the review data
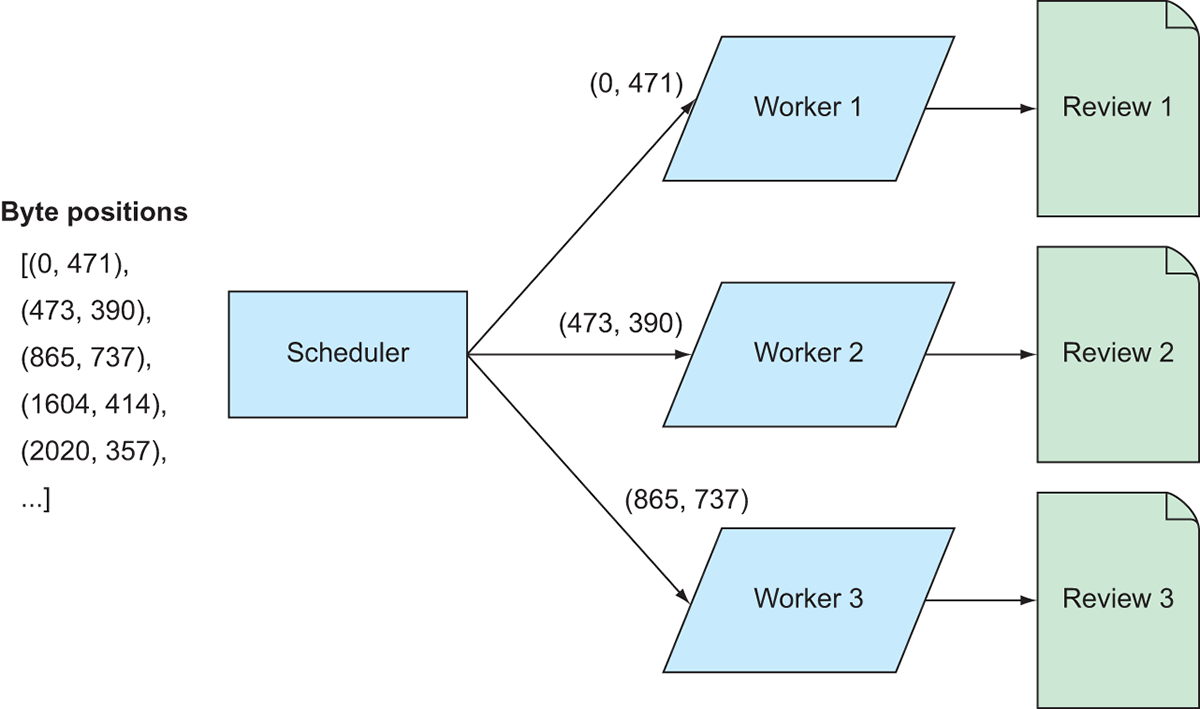
Effectively, the list of addresses will be divided up among the workers; each worker will open the file and parse the reviews at the byte positions it receives. Since the reviews are stored as JSON, we will create a dictionary object for each review to store its attributes. Each attribute of the review looks something like this:
'review/userId: A3SGXH7AUHU8GW\n', so we can exploit the pattern of each key ending in ': ' to split the data into key-value pairs for the dictionaries. The next listing shows a function that will do that.Listing 9.7 Parsing each byte stream into a dictionary of key-value pairs
def get_item(filename, start_index, delimiter_position, encoding='cp1252'): with open(filename, 'rb') as file_handle: #1 file_handle.seek(start_index) #2 text = file_handle.read(delimiter_position).decode(encoding) elements = text.strip().split('\n') #3 key_value_pairs = [(element.split(': ')[0], element.split(': ')[1]) if len(element.split(': ')) > 1 else ('unknown', element) for element in elements] #4 return dict(key_value_pairs) #1 Create a file handle using the passed-in filename. #2 Advance to the passed-in starting position and buffer the specified number of bytes. #3 Split the string into a list of strings using the newline character as a delimiter; the list will have one element per attribute. #4 Parse each raw attribute into a key-value pair using the ': ' pattern as a delimiter; cast the list of key-value pairs to a dictionary.Now that we have a function that will parse a specified part of the file, we need to actually send those instructions out to the workers so they can apply the parsing code to the data. We’ll now bring everything together and create a Bag that contains the parsed reviews.